M1 MacBook Air が届いていろいろやってたら年も明けてだいぶたったけども、ビルド速度とかJava とかDockerとかTensorFlowとか、技術者が気になるベンチマーク を試してたので、まとめました。
なんかM1 Mac 解説動画をとるためにいろいろ調べていたら、悪質サイトのリンクを踏んだみたいで、MacBook Air を買ってしまっていた。
その悪質サイトは最初は7万円台ですよーっていっておいて、結局12万円くらいになっていた。apple.com ってサイトには注意しましょうね。VIDEO www.youtube.com
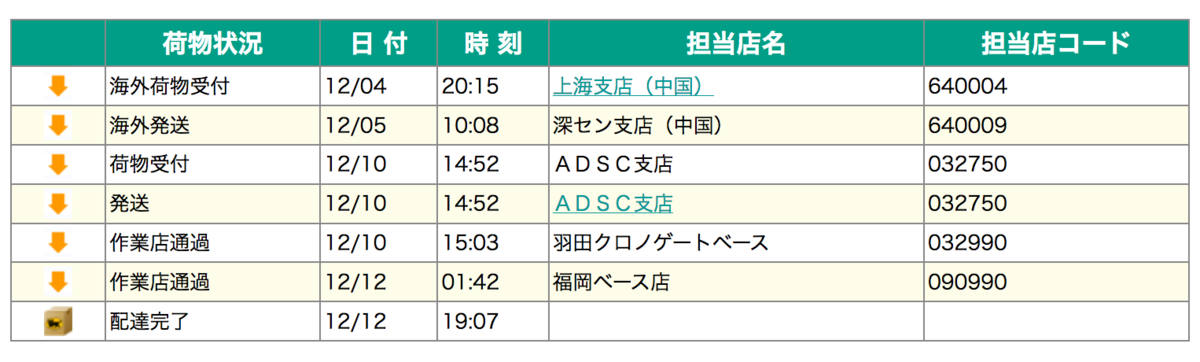
とどいた!
12/12到着予定といいつつ11日になっても羽田から動いてなかったので大丈夫かーと思ったら11日深夜というか12日未明というかそのあたりには福岡に届いてて、朝発想されて夜にとどいた。
でこれだ!
GeekBench も前評判どおりの値がでました。
https://browser.geekbench.com/v5/cpu/5337092
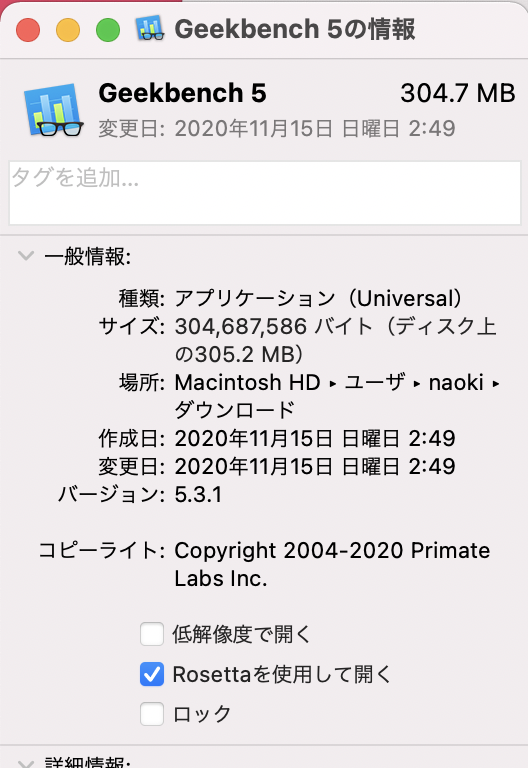
GeekbenchはUniversalAppになってるようで、アプリケーションの情報から「Rosetta を使用して開く」にチェックを入れるとx86 版を動かすことができます。
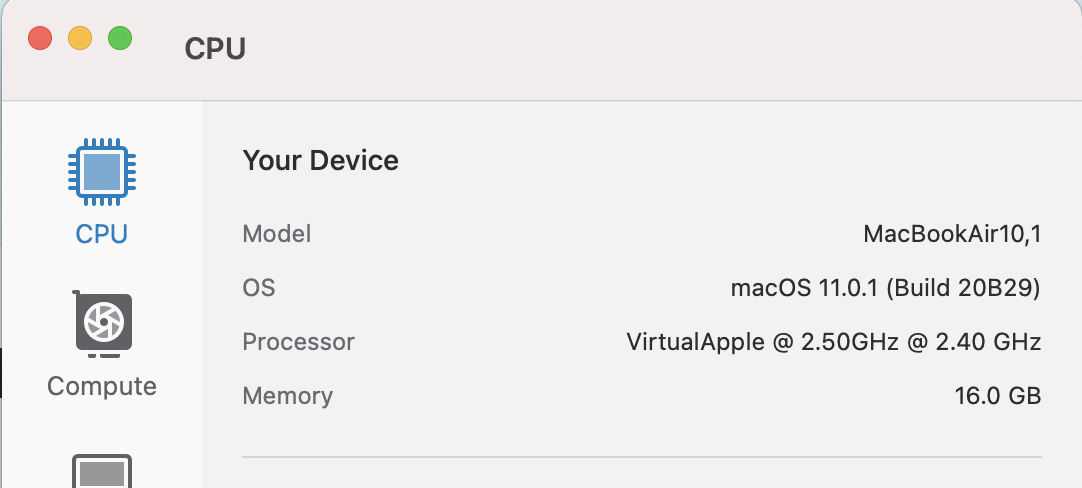
プロセッサがVirtualAppleになっています。
実行すると、Arm版を動かすのとほとんど同じ値が出ていますね。https://browser.geekbench.com/v5/cpu/5337021
あと、7世代8コアi7(i7-7820X)が載ってるWindows と7世代4コアi7(i7-7700HQ)が載ってるMacBook Pro 2017でベンチマーク をとっています。
M1
VirtualApple
i7-7820X
i7-7700HQ
Single-Core
1735
1721
1023
767
Multi-Core
7345
7263
7606
2901
みてわかるのは、シングルスレッド性能は圧倒的に7世代i7たちをしのいでいますね。8コアi7はかろうじてマルチコア性能で勝ってますが、MacBook Pro 2017は完全に圧倒しています。これがエントリモデルであるMacBook Air ていうところがすごいです。
GeekbenchはGPU の計測もできるので比較してみます。 。
M7
RTX2070 Super
Radeon Pro 555Intel HD Graphic 630
16692
94251
13165
4629
さすがにRTX 2070 Superにはぜんぜんかないませんが、MacBook Pro 2017にのってるRadeon Pro 555よりかなりパフォーマンスがいいですね。CPU内蔵のHD Graphicよりはかなりいいです。これがCPU内蔵のGPU ってところがすごい
それでは、Java を動かしてみます。Java のArm Mac 対応はJEP 391 として進められていますが、3月リリースのJava 16には取り込まれず、おそらく9月リリースのJava 17に入ることになると思います。Arm Mac対応のJava を出しているので、これを使って試してみます。
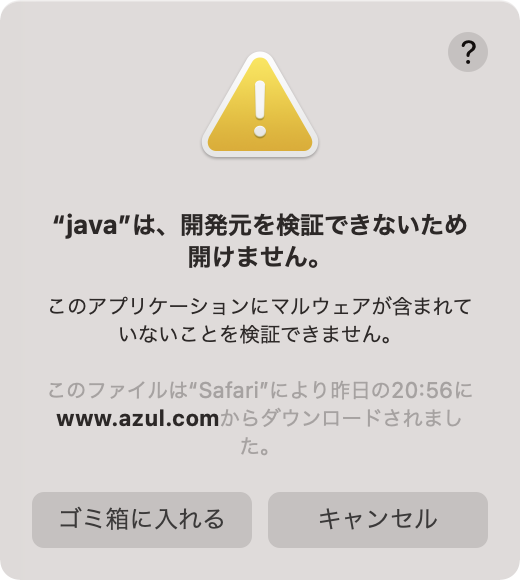
あと、x86 版Java も試してみようと思って、まずはzip版を落としてみるとCPUが違うといわれるました。このメッセージはキャプチャしそこねた。。。Rosetta インストール後は警告が出ます。
で、dmg をインストールしてみたのだけど、ここではAdoptOpenJDK でJava 11を使いました。インストールするときにRosetta のインストール確認が出たのだけど、これもキャプチャしそこね。もったいない。
NetBeans 12.2 がArm Mac に対応したということで、試してみました。
最初はZulu 16eaで動かしたんだけど、すぐ落ちていたので、Zulu 11だと安定しました。
x86 Java on Rosetta でもNetBeans 自体は動きました。
Rosetta で動かすとOSバージョンが10.16になってるの気になる。Arm版だと11.1です。
Arm Java でNetBeans を動かしてもx86 Java で動かしても、Arm Java でMaven プロジェクトを動かすのは問題ないんだけど、x86 Java でMaven プロジェクトを動かすとなんか怒られます。けどここでキャンセルするとビルドは行われる。
Gradleプロジェクトであれば、Arm Java で動かしてもx86 Java で動かしてもすんなりいけました。
いつもなんだかんだレイトレでベンチマーク を取ってるので、ここでもやってみます。Java で書きなおしたものです。https://github.com/kishida/smallpt4j/blob/original/src/main/java/naoki/smallpt/SmallPT.java
こんな感じの絵が出力されます。(ちゃんと時間をかければきれいになる)
それぞれ計ってみると、こんな感じになりました。単位は秒。
M1
VirtualApple
i7-7800X
i7-7700HQ
9.3
10.7
5.9
14.6
実行時間なので、低いほど性能が高いです。ベンチマーク よりはRosetta 経由で性能劣化してるけど、CPUエミュレーションしてると考えればほぼ遜色ない性能といえると思います。コア数の差でi7-7800Xが有利ですが、MacBook Pro 2017のi7-7700HQよりはかなり速いですね。
メモリアクセスがあったほうがいいかとテクスチャありでも比較してみました。 https://github.com/kishida/smallpt4j
結果はこんな感じで、比率としてはほぼかわらずです。
M1
VirtualApple
i7-7800X
i7-7700HQ
25.2
26.2
14.9
36.5
まあテクスチャ使うといっても、ほぼキャッシュに載ってしまってるのかなという感じでした。
ついでに、Java 16ではSIMD 命令をサポートするVector API が取り込まれているので試してみます。x86 であればAVX命令ですけど、ArmだとNEON ですかね。 Mac でも使えて、doubleであれば2つの値を同時に計算できます。128bit幅ということですね。
レイトレでは3次元のベクトルを処理するために3つの値を同時に計算したいので、float x4にしてみたのですけど、精度不足のせいか変な絵になりました。
参考までに、処理時間としては12.6秒かかっているので、Vector API を使わない場合の9.3秒と比べれば遅くなっています。これはx86 のときも同様なので、まだJIT の性能が出てないのかなという感じです。
Spring Boot
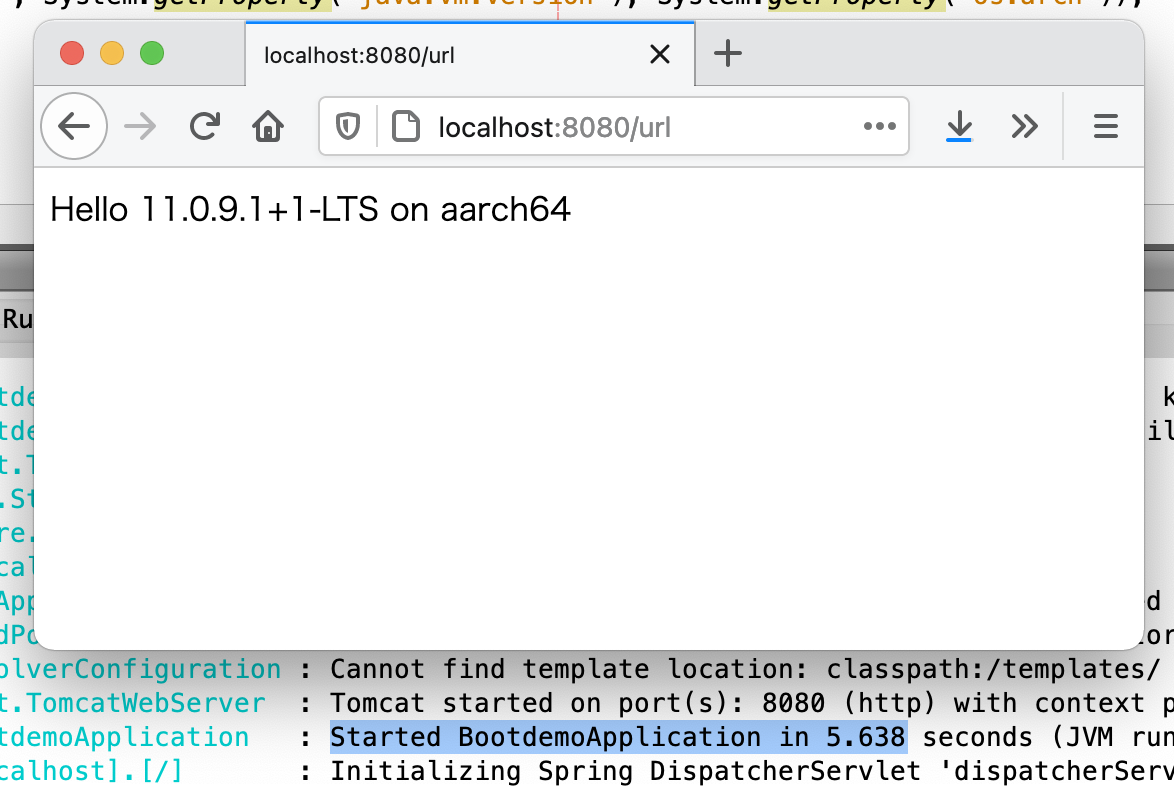
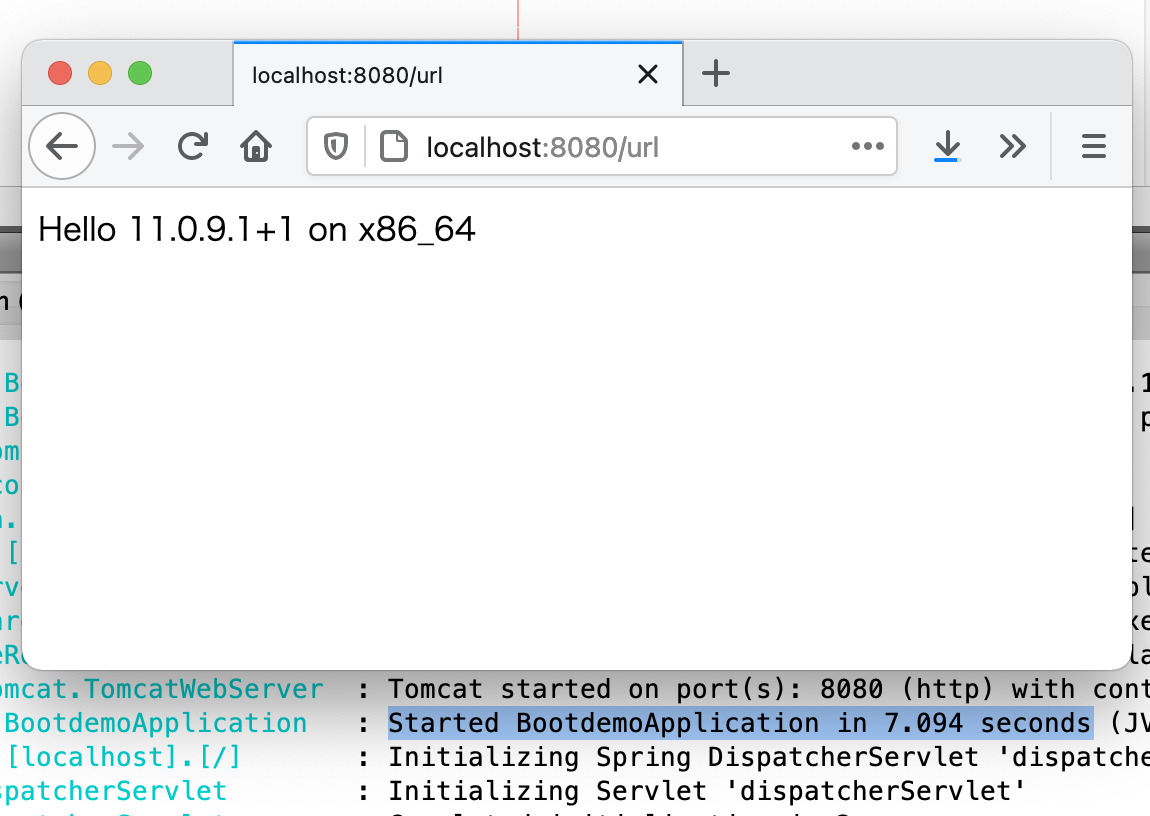
さて、もっと実用的なものということでSpring Bootを動かしてみます。Spring Initializer でSpring Webを含めて作ったプロジェクトに簡単なコントローラを追加して起動時間を計っています。
@RestController
@RequestMapping( "/url" )
public class NewRestController {
@GetMapping
String hello() {
return String.format("Hello %s on %s" ,
System.getProperty("java.vm.name" ),
System.getProperty("os.name" ));
}
}
Arm JDK だと起動に5.6秒かかってます。
x86 JDK on Rosetta だと7秒
i7と比較してみると、やたら遅い感じです。
M1
VirtualApple
i7-7800X
i7-7700HQ
5.6
7.1
1.5
1.5
Rosetta でも遅くなってるというのはありますが、MacBook Pro 2017と比べてもかなり遅くなっています。
見ているとAttaching agents: []のところで5秒かかっている感じです。なんらかセキュリティ機能でひっかかってるんでしょうか。
こちらでDockerで動かしたものと比較していますが、Dockerで動かした場合にはかなり起動が速くなっているので、プロセッサの問題ではなく、なんらかOSの問題でひっかかってるんではないかと思います。Jibで作ったx86イメージがM1 Macで不安定。あとM1 BigSurでSpring Bootの起動が遅い - きしだのHatena
Kafkaのビルド
なんかまとまったソースのビルドのビルドを試そうと思って、Scala のソースがいいなとKafkaをビルドしてみました。https://kafka.apache.org/downloads
./gradlew releaseTarGzしています。
Rosetta 経由だと表示が違うのは なんなんだろう?
--scanをつけて各タスクの時間を見るとこんな感じ。Mac 。
こっちがi7-7800X Windows。
結果をまとめるとこんな感じ。
M1Macはかなり速く、8コア i7の倍速以上になっていますね。コードのビルドは一般にマルチスレッド化しづらい処理なので、シングルコア性能が出ているんではないかと思います。Rosetta はかなり遅く2.5倍の差がついていますね。レイトレではほとんど差がなかったので、シングルスレッドだとJIT 結果が共有できなくて遅いとかディスクアクセスなどが弱いとかなんでしょうか。とはいえ、MacBook Pro 2017より速いので、実用上十分といえるのかもしれません。
Docker
DockerのM1 Mac 対応はTech Preview として開発されています。https://docs.docker.com/docker-for-mac/apple-m1/
Mac のDockerではx86 イメージもArmイメージも動かせます。
x86 Mac の場合ArmイメージはQEMU で、M1 Mac の場合はx86 イメージをQEMU で動かします。
ということで先ほどのレイトレをDockerで動かしてみます。https://gist.github.com/kishida/0842ce696fc58b9809405d6714e0d7c9
JDK はGraalVMを使います。 https://github.com/graalvm/graalvm-ce-builds/releases/tag/vm-20.3.0
比較してみるとこんな感じ
M1
QEMU /Rosetta i7-7800X
i7-7700HQ
Docker
9.4
3M32.3
7.3
18.8
Host
9.3
10.7
5.9
14.6
まあなんか、ホスト側とほとんどかわらないですけど、x86 イメージをQEMU 経由で動かしたものはかなり遅いです。トロール できるRosetta と違って、OSごとのエミュレートだと不利なんだろうなという感じですね。複雑な処理が必要なものはあまり動かさないほうがよさそう。
Native Imageビルド
GraalVMにはJava のコードをネイティブバイナリにコンパイル する機能があります。
native-imageコマンドで、先ほどのレイトレーシング をネイティブ化してみます。
root@f9268a585b9a:/src# native-image SmallPT
[smallpt:235] classlist: 949.93 ms, 0.96 GB
[smallpt:235] (cap): 300.72 ms, 0.96 GB
[smallpt:235] setup: 951.14 ms, 0.96 GB
[smallpt:235] (clinit): 115.10 ms, 1.22 GB
[smallpt:235] (typeflow): 4,217.23 ms, 1.22 GB
[smallpt:235] (objects): 3,925.83 ms, 1.22 GB
[smallpt:235] (features): 181.08 ms, 1.22 GB
[smallpt:235] analysis: 8,624.17 ms, 1.22 GB
[smallpt:235] universe: 266.92 ms, 1.22 GB
[smallpt:235] (parse): 736.24 ms, 1.56 GB
[smallpt:235] (inline): 947.00 ms, 1.56 GB
[smallpt:235] (compile): 4,792.27 ms, 1.53 GB
[smallpt:235] compile: 6,779.24 ms, 1.53 GB
[smallpt:235] image: 769.52 ms, 1.52 GB
[smallpt:235] write: 97.46 ms, 1.52 GB
[smallpt:235] [total]: 18,542.54 ms, 1.52 GB
18秒かかってますね。
x86 イメージをQEMU で動かした場合には、途中でコアダンプ吐いたりして、ネイティブ化ができませんでした。
M1
QEMU i7-7800X
i7-7700HQ
18.5
N/A
22.1
42.4
ビルド時間を比べてみると、8コアであるi7-7800Xよりも速くビルドが通っています。やはりシングルスレッド性能が出たのではないかと思います。
実行してみるとこんな感じです。QEMU ではあらかじめi7で作成しておいたネイティブイメージを使っています。
M1
QEMU i7-7800X
i7-7700HQ
native-image
21.4
5M28.7
34.2
48.2
Java 9.1
3M54
7.3
19.2
比率
2.4
1.4
4.7
2.5
ネイティブ化するまえ、Java コードで動かした場合にはi7-7800Xのほうが速かったのですが、M1のほうが速くなっていますね。Windows のDockerでなにかボトルネック があるのかな。i7のCPU負荷が80%くらいにしかならなくて、ちゃんとコアが使い切れてない感じでした。 QEMU では差が小さいのが興味深いところ。実際の計算よりもエミュレーション用のなんらかのフットプリントのほうが時間をくってる感じでしょうか。
TensorFlow
M1にはニューラルユニットが載っているので、ニューラルネットワーク の計算も得意なはずです。TensorFlowがM1 Mac に最適化したAlpha版を出しているので、これを試してみます。Releases · apple/tensorflow_macos · GitHub
まずはチュートリアル にある全結合層が2段のネットワークで試してみます。 https://gist.github.com/kishida/dc2c2a1c0eadea6708d991506e6b72d6
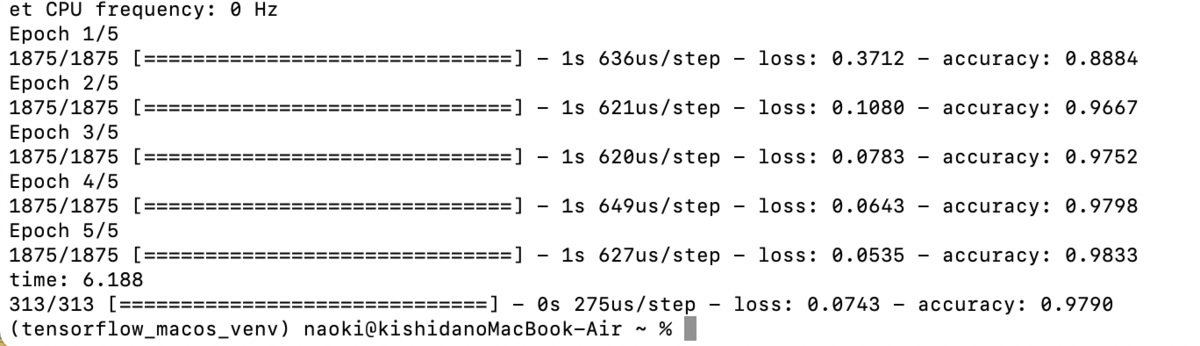
試してみるとこんな感じで6.2秒で終了しました。
なんと、RTX2070 Superより速いですね。
M1
RTX2070 Super
i7-7700HQ
6.2
11.8
19.9
グラフにするとこう
これは恐らく、ネットワークが小さいためRTX2070 Superのコアをほとんど使っておらず、データ転送だけで時間がかかってるのではないかという気がします。
そこで、もっと大きいネットワークを作ってみます。畳み込みニューラルネットワークのチュートリアル にある、
畳み込み層が3層、プーリング層が2層と全結合層が2層の、AlexNetに近いネットワークです。https://gist.github.com/kishida/01d88f72fdf95170294d637d5d6d62f5
実行すると45.385秒になりました。
RTX 2070 Superなどと比較するとこんな感じです。
M1
RTX2070 Super
i7-7700HQ
45.4
22.1
93.6
やはりサイズの大きいネットワークだとRTX 2070 Superより速いということはありませんでしたね。ただ、RTX 2070 Superの倍でしかない、ともいえるし、MacBook Pro 17 2017よりはかなり速いです。ノートパソコンとしてはかなり優秀なんじゃないでしょうか。機械学習 をする場合にもよさそうです。
まとめ
やはり、かなりいいパフォーマンスが出てますね。GPU や機械学習 もノートパソコンとしてはかなり高いパフォーマンスです。QEMU が不安定だったり、改善が必要な点はありますが、かなりよさげです。






































 75mm径 4個入り")






")