fauxpilotというのがあるようなので試してみましたが、やっぱダメ
他の人は動いてるらしいのだけど、何がだめなんだろうか・・・
https://github.com/fauxpilot/fauxpilot
シェルスクリプトで動くので、WindowsではCygwinを使います。
$ git clone https://github.com/fauxpilot/fauxpilot.git $ ./setup.sh
/cygdrive/d/dev/cache/huggingface/hub
$ ./setup.sh
Checking for curl ...
/usr/bin/curl
Checking for zstd ...
/usr/bin/zstd
Checking for docker ...
/cygdrive/c/Program Files/Docker/Docker/resources/bin/docker
Enter number of GPUs [1]:
External port for the API [5000]:
Address for Triton [triton]:
Port of Triton host [8001]:
Where do you want to save your models [/home/naoki/fauxpilot/models]? /cygdrive/d/dev/cache/huggingface/hub
Choose your backend:
[1] FasterTransformer backend (faster, but limited models)
[2] Python backend (slower, but more models, and allows loading with int8)
Enter your choice [1]:
Models available:
[1] codegen-350M-mono (2GB total VRAM required; Python-only)
[2] codegen-350M-multi (2GB total VRAM required; multi-language)
[3] codegen-2B-mono (7GB total VRAM required; Python-only)
[4] codegen-2B-multi (7GB total VRAM required; multi-language)
[5] codegen-6B-mono (13GB total VRAM required; Python-only)
[6] codegen-6B-multi (13GB total VRAM required; multi-language)
[7] codegen-16B-mono (32GB total VRAM required; Python-only)
[8] codegen-16B-multi (32GB total VRAM required; multi-language)
Enter your choice [6]: 2
Downloading the model from HuggingFace, this will take a while...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1159 100 1159 0 0 1110 0 0:00:01 0:00:01 --:--:-- 1112
100 804M 100 804M 0 0 21.6M 0 0:00:37 0:00:37 --:--:-- 22.4M
Config complete, do you want to run FauxPilot? [y/n] y
起動するとこんな感じに。
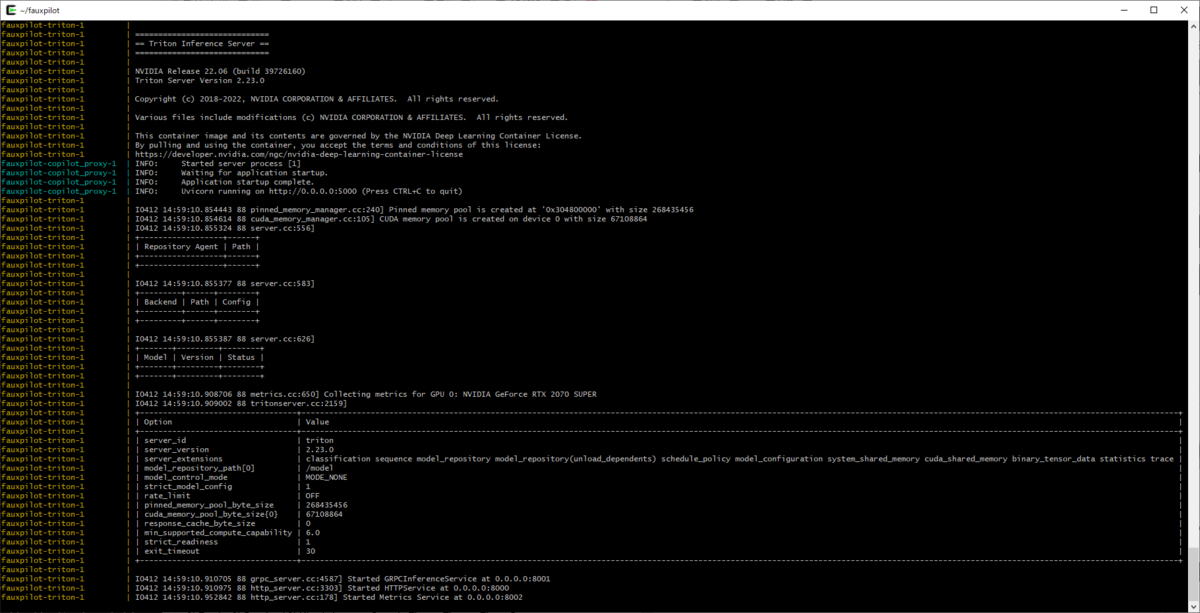
Modelのところとかが空なのが気になる・・・
メモリも割と食ってます。

Dockerイメージも27GBくらい。
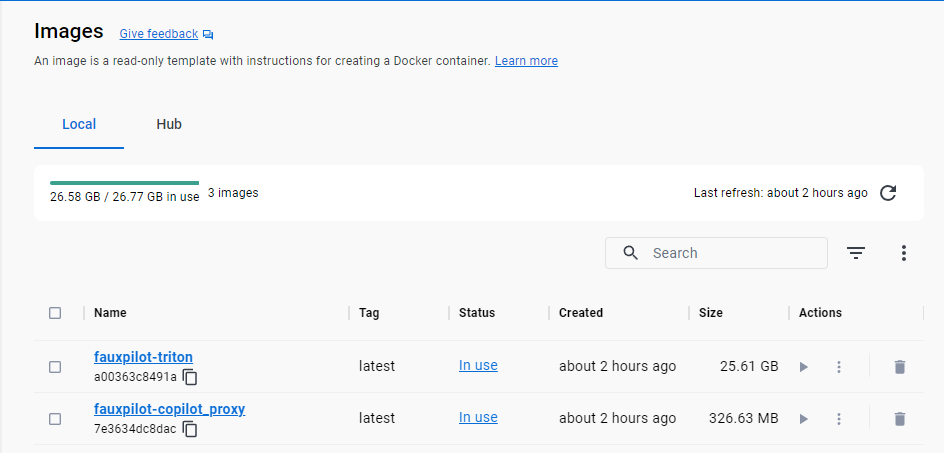
というかこれはtabbyも使っていたNVIDIAのTriton inference serverがメモリやディスクを食ってる感じですね。
2回目以降に起動するときはlaunch.shを動かします。
import openai openai.api_key = 'dummy' openai.api_base = 'http://localhost:5000/v1' result = openai.Completion.create(model='codegen', prompt='def hello', max_tokens=16, temperature=0.1, stop=["\n\n"]) print(result)
なんかダメ。
C:\Users\naoki\Desktop\test>py -3.10 code.py
Traceback (most recent call last):
File "D:\dev\Python\Python310\lib\site-packages\openai\api_requestor.py", line 331, in handle_error_response
error_data = resp["error"]
KeyError: 'error'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\naoki\Desktop\test\code.py", line 4, in <module>
result = openai.Completion.create(model='codegen', prompt='def hello', max_tokens=16, temperature=0.1, stop=["\n\n"])
File "D:\dev\Python\Python310\lib\site-packages\openai\api_resources\completion.py", line 25, in create
return super().create(*args, **kwargs)
File "D:\dev\Python\Python310\lib\site-packages\openai\api_resources\abstract\engine_api_resource.py", line 153, in create
response, _, api_key = requestor.request(
File "D:\dev\Python\Python310\lib\site-packages\openai\api_requestor.py", line 226, in request
resp, got_stream = self._interpret_response(result, stream)
File "D:\dev\Python\Python310\lib\site-packages\openai\api_requestor.py", line 620, in _interpret_response
self._interpret_response_line(
File "D:\dev\Python\Python310\lib\site-packages\openai\api_requestor.py", line 683, in _interpret_response_line
raise self.handle_error_response(
File "D:\dev\Python\Python310\lib\site-packages\openai\api_requestor.py", line 333, in handle_error_response
raise error.APIError(
openai.error.APIError: Invalid response object from API: '{"detail":[{"loc":["body","model"],"msg":"string does not match regex \\"^(fastertransformer|py-model)$\\"","type":"value_error.str.regex","ctx":{"pattern":"^(fastertransformer|py-model)$"}}]}' (HTTP response code was 422)
422が出てますね。
"POST /v1/completions HTTP/1.1" 422 Unprocessable Entity
curlで動かしてみる。
curl -s -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"prompt":"def hello","max_tokens":100,"temperature":0.1,"stop":["\n\n"]}' http://localhost:5000/v1/engines/codegen/completions
こんな警告かえってきて、補完できてない感じ。
{"id": "cmpl-ytIoxgvVETvAPAeJ6tRHBiAwxMRan", "choices": []}
なんか警告でている。fastertransformerが設定されてるけどないからfastertransformerが設定されてることを確認しろ、といってる。fastertransformerが読み込めてない説
WARNING: Model 'fastertransformer' is not available. Please ensure that `model` is set to either 'fastertransformer' or 'py-model' depending on your installation
あと、Curlではenginesが入ったURLを指定してるけど、openaiモジュールからはengines入ってないURLにいってますね。
ということで、なんかダメそう。
ついでに、JavaのtheokanningさんのOpenAIライブラリでローカルのサーバーにつなぐのをがんばったやつ。
OkHttpClient client = OpenAiService.defaultClient("dummy", Duration.ZERO);
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("http://localhost:5000/")
.client(client)
.addConverterFactory(JacksonConverterFactory.create(
OpenAiService.defaultObjectMapper()))
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.build();
getToken();
OpenAiApi api = retrofit.create(OpenAiApi.class);
OpenAiService service = new OpenAiService(api, client.dispatcher().executorService());
dependencyはこんな感じに。
<dependency>
<groupId>com.theokanning.openai-gpt3-java</groupId>
<artifactId>service</artifactId>
<version>0.12.0</version>
</dependency>
<dependency>
<groupId>com.squareup.retrofit2</groupId>
<artifactId>converter-jackson</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>com.squareup.retrofit2</groupId>
<artifactId>adapter-rxjava2</artifactId>
<version>2.9.0</version>
</dependency>