CyberAgentが日本語LLMを公開していたので、とりあえず動かしてみました。
サイバーエージェント、最大68億パラメータの日本語LLM(大規模言語モデル)を一般公開 ―オープンなデータで学習した商用利用可能なモデルを提供― | 株式会社サイバーエージェント
モデルは次のように6サイズ提供されています。

※ Rinna社も同時に新しいモデルを出したので試しています。
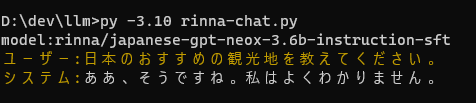
Rinnaの新しい3Bモデルを試してみる - きしだのHatena
open-calm-small(160M)
まずはopen-calm-small。160Mパラメータです。

このあたりは動作確認用なので、内容は気にしない。
GPUメモリは1.3GBくらいの消費です。

open-calm-medium(400M)
次にopen-calm-medium。400Mパラメータです。

このへんも細かいことは気にしないけど、なんかまともなことを書きだしている。
GPUメモリは1.8GBくらいの消費。

open-calm-large(830M)
opem-calm-large。830Mパラメータです。
 まともなことを言うようになってきていますね。
まともなことを言うようになってきていますね。
GPUメモリは2.7GBくらいの消費。

open-calm-1B(1.4B)
open-calm-1B。1.4Bパラメータです。

LLMは中途半端に大きいと京都を首都にしたがる問題w
東京といったり、広島といったり。

GPUメモリは3.7GBくらい。

open-calm-3B(2.7B)
open-calm-3B。2.7Bパラメータです。
 東京と言ってるけど、なんか哲学的な話をする傾向。
東京と言ってるけど、なんか哲学的な話をする傾向。
繰り返しても東京と答えます。

GPUメモリは6.5GBくらい。8GBメモリのGPUでいけますね。

open-calm-7B(6.8B)
一番大きいopen-calm-7Bです。6.8Bパラメータ。

ちゃんとしたこと言ってる。
一応全部東京と答えているけど、アメリカの首都をニューヨークといったり、それより大きい首都を持つ国に東京ディズニーランドより小さいバチカンが入っていたり、正しくはないですね。

あと、毎回checkpointを読み込むのが気になる。
GPUメモリは14.1GBくらい。ということで16GBメモリを積んだGPUが必要です。

CPUで動かすと、読み込み時に最大で34GBくらいのメモリを消費したので、48GB程度のメモリを積んでないと読み込みがつらそうだけど、一旦読み込んでしまえば32GBメモリで動かせると思います。

返答はまともな気がする。CPU動作にしては返答が速い。

RuntimeError: "LayerNormKernelImpl" not implemented for 'Half'というエラーが出る場合はtorch_dtype=torch.float16を消す必要があります。
メモリ消費量(5/19追記)
パラメータ数とGPUメモリ消費量の関係はこうなっています。パラメータ数の2倍よりちょっと多い、という感じですね。

まとめ
実際は用途にあわせてFine Tuneして使うのだと思うけど、そのための基盤モデルが出たのはいいですね。
あと、7Bに関してはGPUメモリ16GBにおさまるように調整しているように思います。RTX 4080でも16GBだし、7月くらいにRTX 4060 tiの16GB版が出るという噂があるのでそれで試しやすくなることを狙っているんじゃないでしょうか。
現状ではRTX 3060の12GB版が一番コストパフォーマンスがいいですが足りない。けどautoが指定されているのでCPUとGPUで振り分けてくれるかもしれません。
うちではA4000使ってます。「遅いけどメモリたくさん」なモデルで電源などの要求が低いので、16GB GPUとしてRTX4080に比べて組み込みやすい。
今回のスクリプトは公式のサンプルに色付けなどちょっと手を加えたものです。float16の指定がされているので大きいモデルでも少ないメモリで動くのだと思います。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from colorama import Fore, Back, Style, init
init(autoreset=True)
model_name = "cyberagent/open-calm-1b"
print ("model:" + model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "アメリカの首都はワシントン。日本の首都は"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(f"{Fore.YELLOW}{prompt}{Fore.WHITE}{output[len(prompt):]}")









")


























 (コロタン文庫)")




