大規模言語モデルの動く様子を見てみて強く反応する部分がわかると、じゃあそこを壊すとどうなるかって試してみたくなるのが当然ですね。
マッドサイエンティストへの道。

ところで、きれいなおねえさん生成モデルのMuse_v1に「mad scientist」と入れると、いい感じのマッドサイエンティスト作ってくれました。
さて、前回のエントリで言語モデルの反応がどうなってるか見てみました。
大規模言語モデルの「脳波」をとって言葉を生成しているときにどこが活動しているのか見てみる - きしだのHatena
その中で、英語の場合に反応する部分、日本語の場合に反応する部分があったので、そこを壊してみるとどうなるか試します。
こんな感じですね。
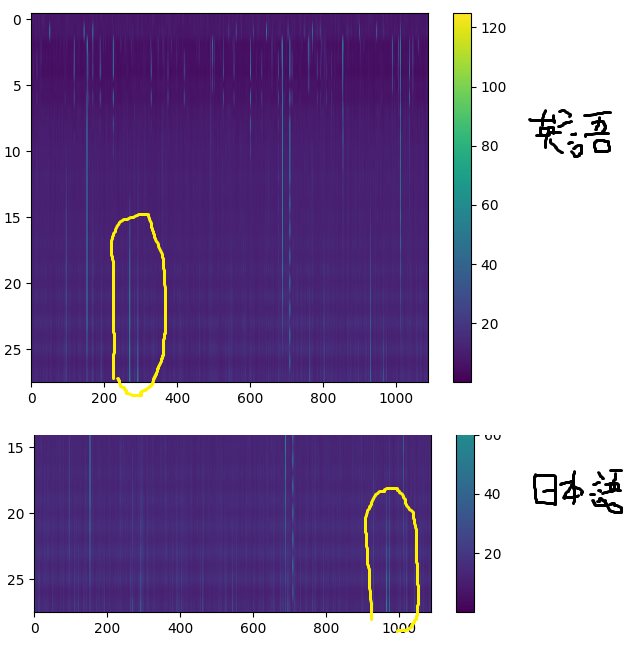
次のようなコードを追加して、11ブロック目から14ブロック目までの265から275、285から295の重みをゼロにします。
各ブロックに2層あるので、上記グラフではy軸が20から27のx軸270あたりということになります。
for idx in range(10, 14): for pidx in list(range(265, 275)) + list(range(285, 295)): model.transformer.h[idx].ln_1.weight.data[pidx] = 0.0 model.transformer.h[idx].ln_2.weight.data[pidx] = 0.0
しかしそんなに壊れませんね。

こんな感じで、狙ったところがゼロリセットされています。

英語は重点的に学習しているので、一部を壊しても影響が少ないのかもしれません。
日本語も、話の内容はよくわかりませんが、日本語っぽいことをしゃべっています。

では、日本語で反応してた部分を壊します。
今度は11ブロック目から14ブロック目までの960-980までの重みをゼロにします。
for idx in range(10, 14): for pidx in range(960, 980): model.transformer.h[idx].ln_1.weight.data[pidx] = 0.0 model.transformer.h[idx].ln_2.weight.data[pidx] = 0.0
日本語がうまくしゃべれなくなりました!

日本語で反応していた部分がゼロになっているのがわかります。

英語は、内容は変ですが文法的にはちゃんと英語になっています。

パラメータの幅としてはどちらも20ほど壊しましたが、反応が強い部分を壊すことで出力に影響があるようです。
また、日本語の学習データがかなり少ないようなので、一部の破壊に敏感になってるのではないかと思います。
Cerebras-GPTの場合、The Pileというオープンソースデータセットを学習に使っていますが、日本語は0.7%だけのようです。
The Pileの構成(なぜCerebras-GPTで日本語が使えるのか?) | ぷるーふおぶこんせぷと
ということで、いろいろいじると楽しいのでみんな遊ぶといいと思う。256Mモデルだと出力はあてにならないけど、メモリもあまりくわずに手軽に遊べます。
