ChatGPTなんかの大規模言語モデルが言葉を生成しているときに、どういう反応が起きているのか気になりますよね。きっと気になる。
ということで、手元で動かせる言語モデルのニューラルネット各層での出力を表示してみました。

GPTにはGPTブロックが複数あって、それぞれのブロックが2層のニューラルネットレイヤを持っています。

モデルを読み込んだあとでこういうコードを動かしてニューラルネットの出力の二乗を足していきます。
for idx, elm in enumerate(model.transformer.h): elm.ln_1.index = idx * 2 elm.ln_2.index = idx * 2 + 1 elm.ln_1.old_forward = elm.ln_1.forward elm.ln_2.old_forward = elm.ln_2.forward def new_forward(self, x): result = self.old_forward(x) ar = result.detach().numpy() summary[self.index] += ar[0][0] ** 2 return result elm.ln_1.forward = new_forward.__get__(elm.ln_1) elm.ln_2.forward = new_forward.__get__(elm.ln_2) tensor1 = elm.ln_1.weight.data tensor2 = elm.ln_2.weight.data summary.append(np.zeros(len(tensor1), dtype=float)) summary.append(np.zeros(len(tensor2), dtype=float))
あとはテキスト生成したあとでグラフ表示
prompt = input("prompt: ") if prompt == "exit": break generated_text = pipe(prompt, do_sample=True, use_cache=True, **opts)[0] print(Fore.YELLOW + prompt + Fore.WHITE + generated_text['generated_text'][len(prompt):]) plt.imshow(np.clip(np.sqrt(summary), 0, range_max), cmap=cmap, aspect='auto') plt.colorbar() plt.show()
今回はCerebras-GPTの256Mモデルを使っています。
「日本の首都は」の続きを生成するとこう。

そしてグラフはこう。

「The capital of Japan is」の続きはこう。

グラフはこう。

わかりにくいですが、前半はほぼ同一、後半ですこし違いがあります。
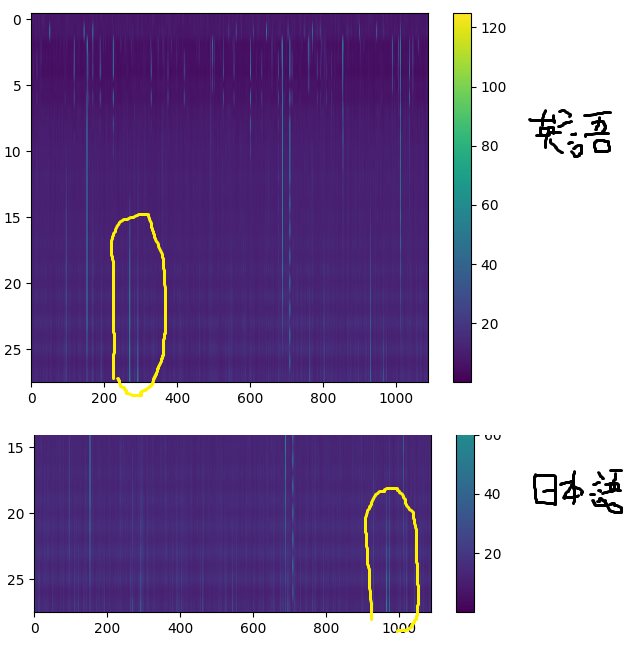
英語では300のあたりが強めに反応しています。一方で日本語だと950あたりが弱めに反応しています。
「今日の天気は」と「weather of today is」、「吾輩は猫」と「I cam a cat」などで生成しても、日本語と英語ではだいたい同じような部分が反応します。
ということで、なんとなく英語を処理する部分と日本語を処理する部分のような、役割による違いがありそうだなーという感じになりました。
あと、英語では反応が強いのだけど、日本語は反応が弱いです。学習量の違いや得意不得意があらわれているように思います。
けどなんか、これは完全に自然科学ですね。
あと、Pythonをぜんぜんわかっていないけど、ChatGPTとCopilotがあれば結構かけるもんなんだなーと思いました。
ソースはこれです
https://gist.github.com/kishida/2f58ff5ad0a75a72597094879d902c08
※追記 どこが反応するかわかるとそこを壊したくなるのが当然なので、やってみました。
大規模言語モデルの「脳波」が反応してる部分を壊すとどうなるか試した - きしだのHatena
