GLM 4.6Vが出てるのでMLXの4bit版を試してみました。
106BのMoEでアクティブパラメータは12B。画像や動画に対応しています。画像エンコーダーもあるので全体では108B。
ライセンスはMIT。
zai-org/GLM-4.6V · Hugging Face
GLM-4.6V: Open Source Multimodal Models with Native Tool Use
日本語表現
小説を書いてもらったら、日本語も流暢で結構いい感じ。
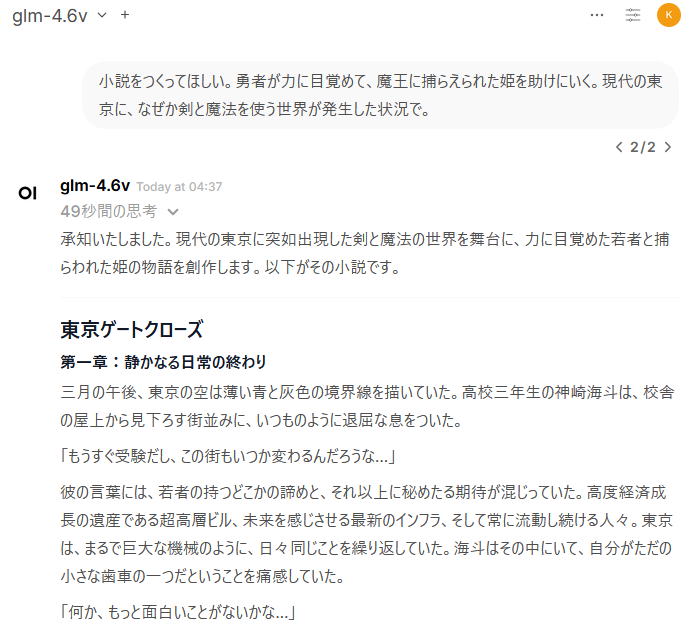
むずかしい問題
「64歳以上であれば100円、64歳未満は1000円」を整数四則演算だけで実現して。 年齢制限なく対応できるように。
ループに入ってしまった。

このあたりはRemaining Issuesにも書いてある。
The model may still overthink or even repeat itself in certain cases, especially when dealing with complex prompts.
コード
いつもどおりブロック崩し。
エラーを一回だしたものの、ちゃんと動くコードが出た。

ただ、Thinkingが長い。最中に一旦コードを出力したりしていた。

そして、ちょっと修正してもらう。
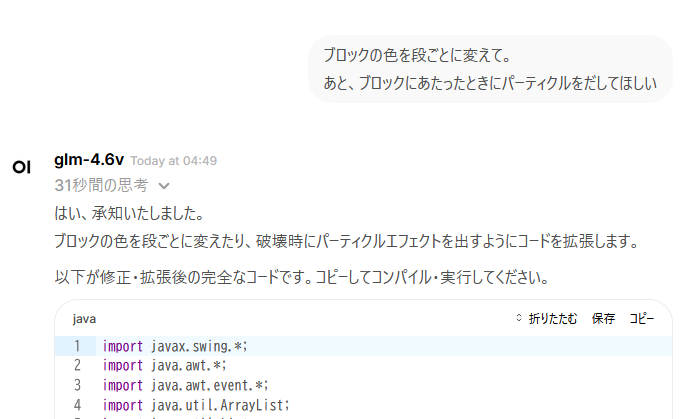
これもすんなり実装してくれた。Thinkingも妥当な内容だった。
かなり安定してコードを書いてくれる印象。
Thinkingの抑制
/nothinkを付けるとThinkingを省略できる。
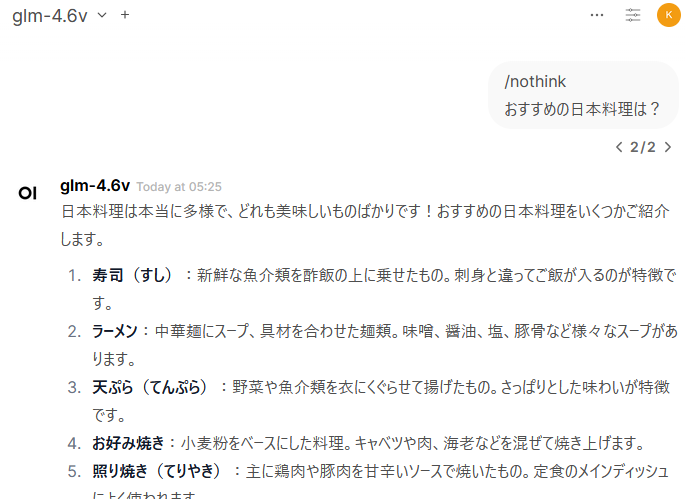
けど、同じことを繰り返したり、ちょっと挙動があやしい。

enable_thinking を設定して抑制もできそうだけど、試してない。
量子化のせいかも。
画像よみとり
日本語読み取り、ほぼ完ぺき。
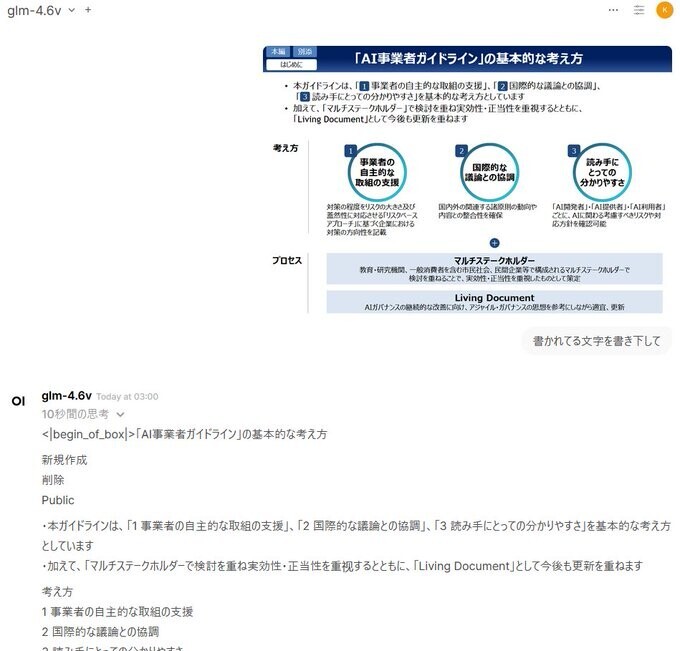
ただ、begin_of_boxのようなコントロールトークン出てしまってます。Jinjaテンプレートにbegin_of_boxがないんで、テンプレートの問題かな。
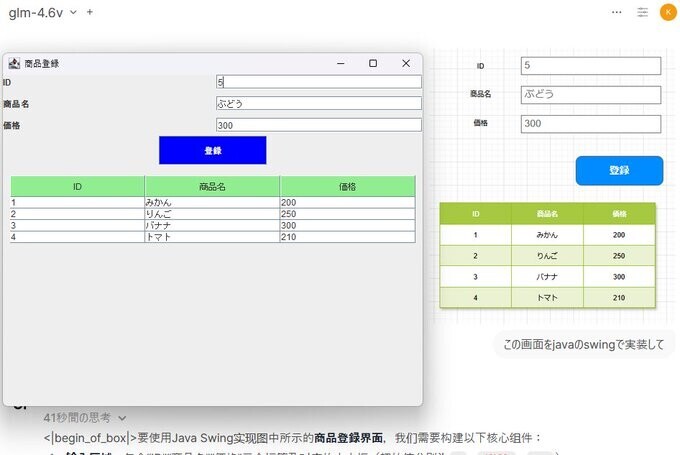
画像を渡してJavaフォームを作ってもらうのも、再現度が高い。
まとめ
最近はGLM 4.5-Airをローカルではメインに使ってるけど、画像付きでバージョンアップした。
100B帯で唯一の画像言語モデルともいえるので、第一選択肢になりそう。
(Llama 4 Scoutが109Bだけど、ライセンスが使いにくいのと性能が低いので・・・)