ChatGPTによるメンバーで構成された仮想のソフトウェア会社にシステム開発を行ってもらうChatDEVが結構おもしろかった。
ChatDEVは、ChatGPTによってCTOやプログラマー、レビュアー、テスターといった役割をもつエージェントをやりとりさせることでソフトウェア開発を自動化しようという試みの実装です。
https://github.com/OpenBMB/ChatDev
アイデアは論文にまとまっていて、こちらで概要が翻訳されています。
[LLM 論文]アプリ全自動開発"ChatDev"の日本語訳|すめらぎ
使い方としては、とりあえずClone
git clone https://github.com/OpenBMB/ChatDev.git
そして依存モジュールのインストール
cd ChatDev pip3 install -r requirements.txt
あと、OpenAIのアクセスキーを環境変数OPENAI_API_KEYに設定しておく必要があります。
export OPENAI_API_KEY="your_OpenAI_API_key"
で、タスクと名前を指定すれば勝手にプログラムができる。
python3 run.py --task "[description_of_your_idea]" --name "[project_name]"
ということで、インベーダーゲームを作ってとやってみました。ここでは英語で指示してるけど、受け取るのはChatGPTなので日本語でも大丈夫です。あと、モデルはデフォルトでGPT-3.5-Turboなのだけど、確実さをもとめてGPT_4を使ったりしています。
python3 run.py --task "design invader game" --name "my-invader" --model GPT_4
ところでこの仮想開発会社、開発がはじまると確認なく最後まで進んで、できましたと納品したあとは修正も受け付けないという、分類するならクソ開発会社なので、タスクはこんな漠然としたものではなく具体的にキャラクタの形状や動作などを指定するほうがいいです。じゃないとなぜかへんなおっさんが・・・
で終わったらWareHouseフォルダのなかのアプリケーション名で始まるフォルダにいってmain.pyを起動すればOK
cd WareHouse/my-invader_DefaultOrganization_20230901092058
python main.py
ということで、まずGPT3.5-turboでやったのがこれ。
10分かかったのを20倍速にしてます。で、できたぞと思ったら・・・
ChatDevおもしろい。「インベーダーゲーム作って」といったら、仮想CTOが方針きめて仮想プログラマが実装して仮想レビュアーがレビューして仮想テスターがテストして10分ほどでなんか作ってきた。なお成果物・・・GPT3.5だったから、GPT4でやりなおしてみよう。
— きしだൠ(K1S) (@kis) 2023年9月1日
動画は20倍速 pic.twitter.com/myE7kCemOM
へんなおっさんが横移動してミサイル置いていくアプリになっていましたw
おっさんバージョンをゆっくりみたい人のために。 pic.twitter.com/KhAXRTM8GQ
— きしだൠ(K1S) (@kis) 2023年9月1日
課金は$0.16でした。25円くらい。
気を取り直してGPT4を指定したのだけど、最初はファイルひとつまるごと実装もれしていて、やりなおしたら動きそうなコードができていました。
画像ファイルがなかったので、Windowsのペイントで書いています。あと、ミサイルが動かないのを修正したり、実行速度を調整したりして、こんな感じに。
ChatDevにインベーダーつくってとお願いしたの、一回ファイルが足りないものができて、やりなおして、やっと動くものができた。
— きしだൠ(K1S) (@kis) 2023年9月1日
画像が足りなかったので、これは自分でMS Paingで描いた。あと、弾が動かなかったので修正と、動きが速すぎたのでウェイトいれた。 pic.twitter.com/u3hV1siQhx
課金はやりなおし含めて$1.5増えていたので、200円かかっていますね。
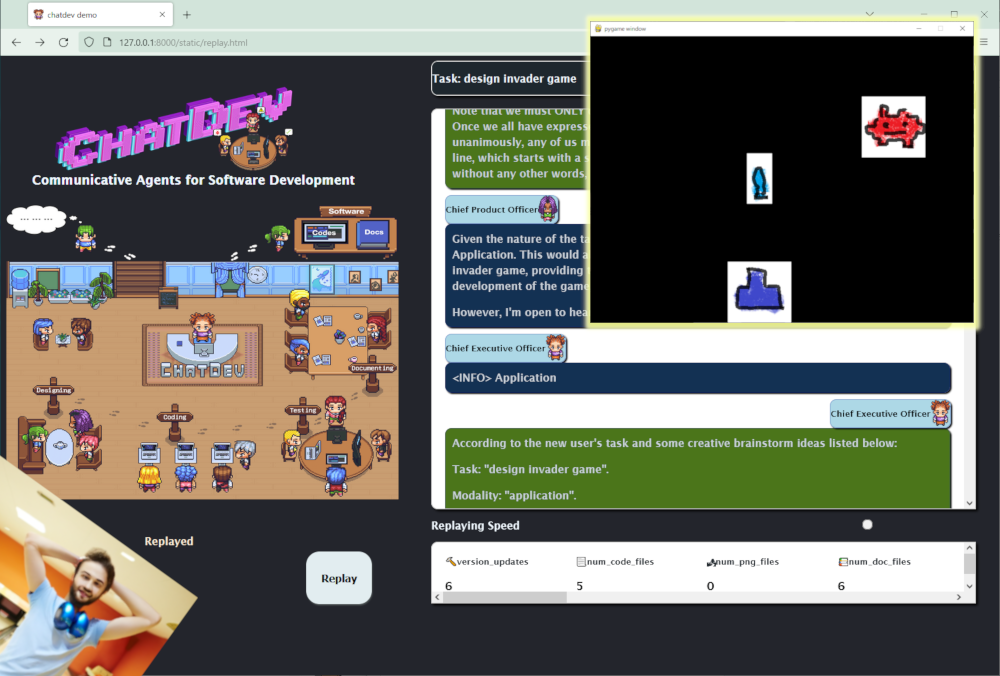
実行ログを可視化することもできます。次のコマンドでビュワーを開いて、Chat Replayでログをアップロードすればいろいろ再現されます。
python3 online_log/app.py
こんな感じ。最初にCTOがデザインしてプログラマにタスクが渡り、レビュワーにレビューしてもらって、動くようになったらテスターがテスト、最後にドキュメントを書いて左側でソファに座ってるクライアントに納品という流れ。
失敗ふくめて$1.5かかってるから、200円でできているw
— きしだൠ(K1S) (@kis) 2023年9月1日
ログの可視化もあった。
真ん中下部で左むいてるCTOがプログラマに指示だして、真ん中下部のプログラマがコード書いて、左の島の上のレビュワーがレビュー、動くようになったら島の下のテスターがテスト。 pic.twitter.com/FDKvaFDgWx
まあ、実際には、ふつうにChatGPTに直接指示して作っていくほうが確実だし変なものになりづらいのだけど、これはコンセプトモデルなので、途中に人間が確認するフェーズを入れるとか、仮想環境をたててテスト起動をするとかいろいろ作りこめば、プログラム知らない人でもある程度のモノが作れる感じだなーと思いました。
この本には、LangChainによるエージェントでいろいろタスクを実現するデモまで載ってるけど、それの発展形という感じですね。






")



























")