Llama2をコーディング用にチューニングしたCode Llamaでてますね。
そして、対話モデルもあります。
けどどう使うかわからなかったのでいろいろ試したら、なんとなくわかったのでメモ。
モデルはHugging Faceにあるので、ふつうのTransformersモデルとして使えます。
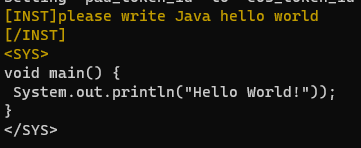
で、指示文は[INST]~[/INST]で囲む、システムからの出力は<SYS>から</SYS>で囲まれるという感じぽい。
ので、プロンプトをこんな感じで作る。
prompt = f"""[INST]{prompt}[/INST] <SYS>
コード全体はこうなります。
import torch from transformers import AutoModelForCausalLM, AutoTokenizer from colorama import Fore, Back, Style, init model_name = "codellama/CodeLlama-7b-Instruct-hf" model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16).cuda() tokenizer = AutoTokenizer.from_pretrained(model_name) prompt = """please write Java hello world """ prompt = f"""[INST]{prompt}[/INST] <SYS> """ inputs = tokenizer(prompt, return_tensors="pt").to(model.device) with torch.no_grad(): tokens = model.generate( **inputs, max_new_tokens=100, do_sample=True, temperature=0.8, pad_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id, ) output = tokenizer.decode(tokens[0], skip_special_tokens=True) print(f"{Fore.YELLOW}{prompt}{Fore.WHITE}{output[len(prompt):]}")
VRAMは15GBくらい使います。
出力はこんな感じ。JavaのHello world、仕様が新しすぎんか?