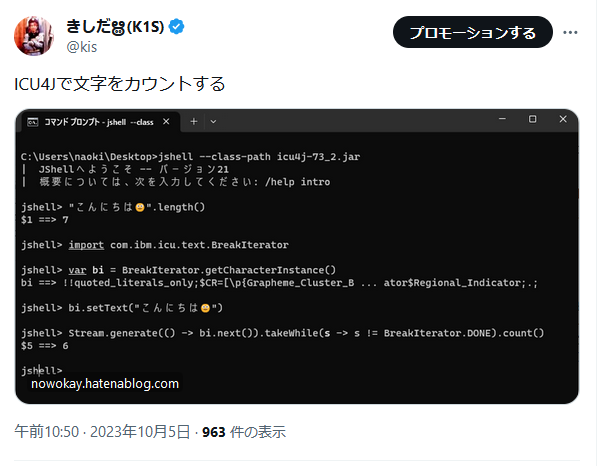
ChatGPTが画像対応して、画像からいろいろなコードが生成できて楽しいことになっていましたが、同じようなことをおうちで動かせるLLaVAが出ていたので試してみました。
GPUはVRAM 12GBあれば十分、8GBはギリギリという感じ。

LLaVA-1.5
先週、LLaVAのバージョンアップ版、LLaVA-1.5が出てました。
🚀 LLaVA-1.5 is out! Achieving SoTA on 11 benchmarks, with simple mods to original LLaVA! Utilizes merely 1.2M public data, trains in ~1 day on a single 8-A100 node, and surpasses methods that use billion-scale data.
— Haotian Liu (@imhaotian) 2023年10月6日
🔗https://t.co/y0kG0WZBVa
🧵1/5 pic.twitter.com/kMz0LTk63R
LLaVAはマイクロソフトやウィスコンシン大学が開発しているマルチモーダルモデルです。
LLaVA: Large Language and Vision Assistant - Microsoft Research
デモはここ。
https://llava.hliu.cc/
このデモをおうちのWindowsで動かそうというのが今回のブログの趣旨
セットアップ
基本的にはGitHubの手順に従います。
https://github.com/haotian-liu/LLaVA
まずはClone
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
で、venvやらcondaの環境をお好みで。
python -m venv .venv
.venv\Scripts\activate.bat
そしてpip install -e .するのだけど、deepspeedはWindowsに対応していなくてインストール時にエラーが出るので、pyproject.tomlから消しておきましょう。
https://github.com/haotian-liu/LLaVA/blob/main/pyproject.toml#L20
あと、PyTorchがGPU非対応のものが入ってしまうので、自力でインストールします。
PyTorchのサイトを確認。
https://pytorch.org/
CUDA 11.8が入ってるとして、次のようにします。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
bitsandbytesもWindows用バイナリが足りないものが入ってしまうので、これも自力で。
bitsandbytes-windows-webuiのバイナリを使います。
https://github.com/jllllll/bitsandbytes-windows-webui
pyproject.tomlでは0.41.0という指定になっているので、次のように。
python -m pip install bitsandbytes==0.41.0 --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webui
これでようやくpip installができます。
pip install --upgrade pip pip install -e .
コマンドラインで試す
Web UIも用意されてるけど手順がめんどいので、まずはコマンドラインで試します。改行してるけど、一行で。
python -m llava.serve.cli --model-path liuhaotian/llava-v1.5-7b --image-file llava/serve/examples/extreme_ironing.jpg --load-4bit
7Bモデルを4bitで読み込んでいます。画像として指定しているのはタクシーの後ろでアイロンかける人ですね。
結果はこんな感じに。

Google翻訳するとこうなりました。
この画像の珍しい点は、男性が走行中の黄色いタクシーの後ろに立って、衣服にアイロンをかけていることです。 衣類のアイロンがけは通常、家や洗濯室などの室内で行われるため、これは典型的な場面ではありません。 走行中の車両の中で衣服にアイロンをかけるという男性の行為は異例であり、事故や怪我につながる可能性があり、潜在的に危険です。
メモリは、3.6GB使っていた状態から読み込み時点では8.5GBに、そして上記の結果を出力するときに10GBになっていたので、6.4GB使った感じですね。なので8GB VRAMでいけそう。
RTX 4060 Ti 16GBでのスピードはこんな感じです。
7B 4bit pic.twitter.com/c5ki245HWB
— きしだൠ(K1S) (@kis) 2023年10月12日
すごく雑には、こんな感じでメモリ使ってました。13B 8bitは16GBだと少しはみでて遅くなっている感じ。
| モデル | 7B | 13B |
|---|---|---|
| normal(16bit) | 15GB | 26GB? |
| load-8bit | 11GB | 18GB? |
| load-4bit | 7GB | 11GB |
Web UIで試す
さて、Web UI。3つ起動が必要でめんどい。
まずコントローラー
python -m llava.serve.controller
21001番ポートで起動します。

次にモデル管理のためのmodel_worker。
ただ、Windowsの日本語環境で実行すると、ログでエラーがでてそのエラーのログでエラーが出て、となって正常に動かないので、llava/utils.pyを修正します。
50行目にencoding='UTF-8'を追加します。プルリク出しているので、ここを参考に。
https://github.com/haotian-liu/LLaVA/pull/556/files
そしたら、こんな感じで動かします。ここでは13Bを4bitで読み込ませてます。実際には1行で。
python -m llava.serve.model_worker --model-path liuhaotian/llava-v1.5-13b --load-4bit
21002番ポートで起動します。

最後にWeb UI
python -m llava.serve.gradio_web_server --model-list-mode reload
7860番ポートで起動します。

この画像を投げて「write docker compose」と指定してみます。

なんかdocker composeファイルを書いてくれました!

動きとしてはこんな感じ。上記と別のタイミングの動画なので、内容はちょっと違います。
わいわい!
— きしだൠ(K1S) (@kis) 2023年10月12日
おうちのパソコンが図からDocker composeを書いてくれた!動画は、実時間ノーカット。 pic.twitter.com/Z6sS0EWnXX
これでローカルでもいろいろできそうです!


![[改訂新版]プログラマのための文字コード技術入門 (WEB+DB PRESS plusシリーズ)](https://m.media-amazon.com/images/I/51vqn-2eVKL._SL500_.jpg "[改訂新版]プログラマのための文字コード技術入門 (WEB+DB PRESS plusシリーズ)")















")