CTranslate2はTransformerモデルをCPUやGPUで効率的に動かすライブラリです。
https://github.com/OpenNMT/CTranslate2
CTranslate2の機能のひとつにモデルの量子化があります。INT8で量子化すると雑に必要メモリが半分に。そしてCPUでも動かしやすくなるので、GPUなくてもLLMが試しやすくなります。
まあ、INT8を使うだけだと、モデルの読み込み時のfrom_pretrainedにload_in_8bit=Trueをつければいいのだけど、これがbitsandbytesというライブラリを使ってて、そしてbitsandbytesがWindowsに対応していない。*1
一応、有志がビルドしたDLLを使えば動くのだけど、めんどい。
https://qiita.com/selllous/items/fbaa2c3d2d504e436b17
CTranslate2だとちゃんとWindowsで動くので安心。
とりあえずpipでctranslate2をインストール。
> pip install ctranslate2
変換
そうするとct2-transformers-converterでHugging Faceのモデルが変換できる。
> ct2-transformers-converter --model rinna/japanese-gpt-neox-3.6b-instruction-ppo --quantization int8 --output_dir rinna-ppo-ct2
このとき、出力先のフォルダが存在していたら怒られます。--forceをつけましょう。
モデル名はHugging Faceに行ってコピーするのが確実。
https://huggingface.co/rinna/japanese-gpt-neox-3.6b-instruction-ppo
ちょっと待つと変換できます。1パラメータ8bitなので、パラメータ数GBのファイルができる感じです。
変換時にはメモリを食って26GBくらい使うっぽいので、32GBほしいところ。
と思ったら--low_cpu_mem_usageというオプションを見つけたので、これをつけると16GBメモリでいけそう。
メモリ消費をおさえると時間かかるかなと思ったけど、そんなこともなかった。
動かす
RinnaモデルはGPT-NeoXアーキテクチャなので、このソースが使える。
https://opennmt.net/CTranslate2/guides/transformers.html#gpt-neox
tokenizerの読み込み時にuse_fast=Falseをつけたり、トークナイズ時にadd_special_tokens=Falseが必要だったりで、こんな感じに。
import ctranslate2 import transformers model_name = "rinna/japanese-gpt-neox-3.6b-instruction-ppo" ct2_model = "rinna-ppo-ct2" generator = ctranslate2.Generator(ct2_model) tokenizer = transformers.AutoTokenizer.from_pretrained(model_name, use_fast=False) prompt = "ユーザー: 日本の首都はどこ?<NL>システム :" tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt, add_special_tokens=False)) results = generator.generate_batch( [tokens], max_length=256, sampling_topk=20, sampling_temperature=0.7, ) text = tokenizer.decode(results[0].sequences_ids[0]) print(text)
GPUで動かす
generatorの読み込み時にdevice='auto'か、明示的にdevice='cuda'とすればGPUで動きます。
generator = ctranslate2.Generator(ct2_model, device='auto')
けど、ここでCUDAのバージョンが11.xである必要があります。
12.1と11.2が入っていたので、11.2がPATHで最初に来るように変更。
しかし、なんかcublas64_11.dllがないというエラーが。
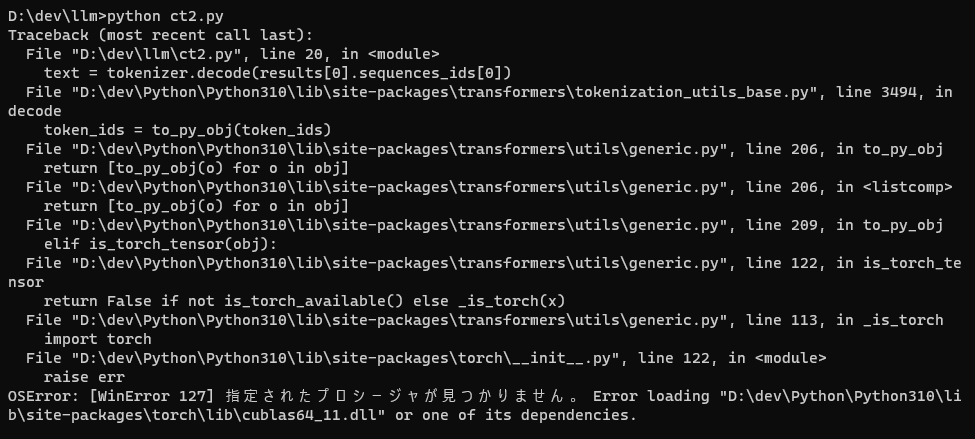
torch/libにはcublas64_11.dllがあるのに不思議とおもいつつ確認してると、CUDA/v11.2/binにあるcublas64_11.dllとサイズが違うことに気づいたので、v11.2にあるものをtorch/libにコピー。
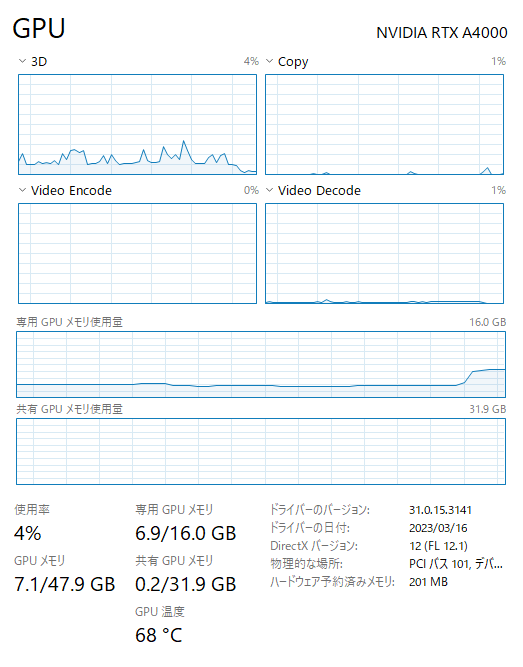
ちゃんと動きましたん。
Firefoxが2.5GBくらい使っていたので、4GBちょいで動いた模様。なので8GBのGPUでも動かせそう。
Gradioでブラウザから使う
Gradio、素敵
https://gradio.app/
def generate(input): ... return text
のような関数を作って
llm = gr.Interface(
fn = generate,
inputs = gr.Textbox(lines=3, placeholder="質問を入力してください"),
outputs = gr.Textbox(lines=3),
)
llm.launch()
という感じで関数への入出力に対応するUIを指定してあげるだけでこんなUIができる。
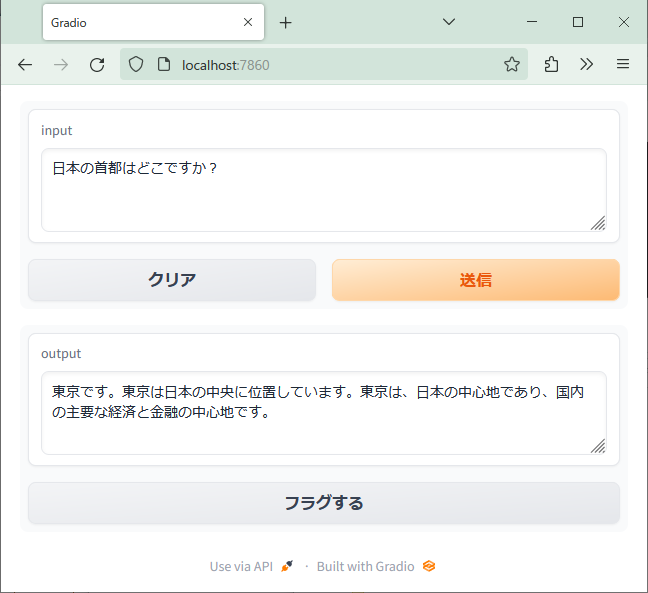
CPUだと15秒くらいで答えが返ってくる。 i7-7820Xなので、もっと新しいCPUであれば10秒切るんじゃなかろうか。
CTranslate2で変換したrinna ppo、CPUでも割と速く返答する。それなりの文章が15秒くらい。メモリも5GB使わない感じ。
— きしだൠ(K1S) (@kis) 2023年6月14日
ただし変換には32GBくらいのメモリが必要。 pic.twitter.com/ZaKx0UvWKg
CPUでLLMを動かすというとllama.cppがありますが、やはりPythonのエコシステムが使えるのは いいですね。
GPUだと7秒くらい。A4000は結構遅いので、RTX40とかRTX30とか普通のゲーム用GPUであればもっと速そう。
GPUだともっと速いけど倍くらい?これはA4000の処理がそんなに速くないからかも。
— きしだൠ(K1S) (@kis) 2023年6月14日
「彼はとても優しいです」が繰り返されたのは、つい再生成してしまった。 pic.twitter.com/CMCJrkKIrR
import ctranslate2 import transformers import gradio as gr model_name = "rinna/japanese-gpt-neox-3.6b-instruction-ppo" ct2_model = "rinna-ppo-ct" generator = ctranslate2.Generator(ct2_model, device="cuda") tokenizer = transformers.AutoTokenizer.from_pretrained(model_name, use_fast=False) def generate(input): prompt = "ユーザー :" + input + "<NL>システム :" tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt, add_special_tokens=False)) results = generator.generate_batch( [tokens], max_length=256, sampling_topk=20, sampling_temperature=0.8, include_prompt_in_result=False, ) text = tokenizer.decode(results[0].sequences_ids[0]) return text llm = gr.Interface( fn = generate, inputs = gr.Textbox(lines=3, placeholder="質問を入力してください"), outputs = gr.Textbox(lines=3), ) llm.launch()
")
*1:2024時点では対応してるけど導入はめんどい