AS300で撮った動画のタイムスタンプがaviutlで読み込めなくてうまくGPSデータが合成できなかったので、GPSデータのタイムスタンプをずらすようにした。 たぶんまた使うので、ブログにメモ
List.of(123, "hoge")の型がこわい。泣きそう。
List.of(123, "hoge")がどんな型になるかを見てみたら、きっとList<Object>になっていて「Objectはどんな値にも対応するんですよー」みたいな説明ができると思っていたら、実際は泣くほど怖い型が出てきた。
List.of(123, "hoge")がどんな型になってるか見ると「Objectは何でも扱えるんですよー」みたいな説明ができるかなと思ったら、泣くほど怖い型が出てきた・・・ pic.twitter.com/Y31F8cdzGH
— きしだൠ(K1S) (@kis) 2021年6月23日
`List<Serializable&Comparable<? extends Serializable&Comparable<?>&java.lang.constant.Constable&java.lang.constant.ConstantDesc>&java.lang.constant.Constable&java.lang.constant.ConstantDesc>
という型になっている。

パッケージ名が邪魔くさいので消してみると
List<Serializable&Comparable<? extends Serializable&Comparable<?>&Constable&ConstantDesc>&Constable&ConstantDesc>
となる。 Genericsは怖いのでComapableのGenericsを消してみるとこんな感じ。
List<Serializable&Comparable&Constable&ConstantDesc>
だいぶ怖くなくなった。
ところで、ConstableとかConstantDescってなんだ?知らない子ですね。
これはJava 12で導入されたConstant APIのインタフェース。
JEP 334: JVM Constants API
Java 11であればこんな感じになる。
jshell> List.of(123, "test") $1 ==> [123, test] jshell> /v $1 | List<Serializable&Comparable<? extends Serializable&Comparable<?>>> $1 = [123, test]
これならわりと怖くない。
ComparableのGenericsを取り除くとList<Serializable&Comparable>となって、これなら付き合ってあげていいかなという気持ちになる。こうやってインラインで書ける。
ところでJava 12以降でも、LocalDateなどとの組み合わせであれば怖くない型になる。
jshell> List.of(123, LocalDate.now()) $2 ==> [123, 2021-06-24] jshell> /v $2 | List<Serializable&Comparable<? extends Comparable<?>>> $2 = [123, 2021-06-24]
LocalDateにはリテラルがないからConstant Poolに入ることがないのでConstableなどが付かないんだろうか。Comparableの中にSerializableがないのもよい。
あと、Streamとの組み合わせであれば望み通りList<Object>が得れる。
jshell> List.of(123, Stream.of()) $3 ==> [123, java.util.stream.ReferencePipeline$Head@5ef04b5] jshell> /v $3 | List<Object> $3 = [123, java.util.stream.ReferencePipeline$Head@5ef04b5]
しかし値がな。
10年目のFizzBuzz改善
ほぼ10年前にFizzBuzzを書いていた。
落ち着かないのでFizzBuzz書いた - きしだのHatena
当時としてはがんばったほうなのだけど、改めてみると改善ポイントがみつかった。
よりコンパクトになった。やはりコピペコードいくない。
あと、オブジェクト指向など実業務では使いものにならない!newなんてムダだってことで、全部staticメソッドにした。
あいかわらず数値は出せてないけども。
package kis.sample; public class FizzBuzz { public static void main(String[] args) { n(0); } static void n(int i){ if(i % 3 == 0){ if(i % 5 == 0){ fizzbuzz(i + 1); }else{ fizz(i + 1); } }else{ if(i % 5 == 0){ buzz(i + 1); }else{ n(i + 1); } } } static void fizz(int i){ // fizzの直後にfizzが来ることはない if(i % 5 == 0){ buzz(i + 1); }else{ n(i + 1); } } static void buzz(int i){ // buzzの直後にbuzzが来ることはない if(i % 3 == 0){ fizz(i + 1); }else{ n(i + 1); } } static void fizzbuzz(int i){ // fizzbuzzの直後はnのみ n(i + 1); } }
結果
Exception in thread "main" java.lang.StackOverflowError
at kis.sample.FizzBuzz.fizz(FizzBuzz.java:28)
at kis.sample.FizzBuzz.buzz(FizzBuzz.java:34)
at kis.sample.FizzBuzz.n(FizzBuzz.java:16)
at kis.sample.FizzBuzz.fizz(FizzBuzz.java:28)
at kis.sample.FizzBuzz.n(FizzBuzz.java:12)
at kis.sample.FizzBuzz.n(FizzBuzz.java:18)
at kis.sample.FizzBuzz.fizzbuzz(FizzBuzz.java:41)
at kis.sample.FizzBuzz.n(FizzBuzz.java:10)
at kis.sample.FizzBuzz.n(FizzBuzz.java:18)
at kis.sample.FizzBuzz.fizz(FizzBuzz.java:28)
at kis.sample.FizzBuzz.n(FizzBuzz.java:12)
at kis.sample.FizzBuzz.buzz(FizzBuzz.java:36)
at kis.sample.FizzBuzz.fizz(FizzBuzz.java:26)
at kis.sample.FizzBuzz.n(FizzBuzz.java:12)
at kis.sample.FizzBuzz.n(FizzBuzz.java:18)
at kis.sample.FizzBuzz.fizz(FizzBuzz.java:28)
at kis.sample.FizzBuzz.buzz(FizzBuzz.java:34)
at kis.sample.FizzBuzz.n(FizzBuzz.java:16)
at kis.sample.FizzBuzz.fizz(FizzBuzz.java:28)
at kis.sample.FizzBuzz.n(FizzBuzz.java:12)
at kis.sample.FizzBuzz.n(FizzBuzz.java:18)
at kis.sample.FizzBuzz.fizzbuzz(FizzBuzz.java:41)
at kis.sample.FizzBuzz.n(FizzBuzz.java:10)
at kis.sample.FizzBuzz.n(FizzBuzz.java:18)
at kis.sample.FizzBuzz.fizz(FizzBuzz.java:28)
at kis.sample.FizzBuzz.n(FizzBuzz.java:12)
at kis.sample.FizzBuzz.buzz(FizzBuzz.java:36)
at kis.sample.FizzBuzz.fizz(FizzBuzz.java:26)
at kis.sample.FizzBuzz.n(FizzBuzz.java:12)
...
M1搭載MacBook Airが届いたのでJavaやDockerなどいろいろベンチマークした
M1 MacBook Airが届いていろいろやってたら年も明けてだいぶたったけども、ビルド速度とかJavaとかDockerとかTensorFlowとか、技術者が気になるベンチマークを試してたので、まとめました。
MacBook Airを買ってしまった
なんかM1 Mac解説動画をとるためにいろいろ調べていたら、悪質サイトのリンクを踏んだみたいで、MacBook Airを買ってしまっていた。
その悪質サイトは最初は7万円台ですよーっていっておいて、結局12万円くらいになっていた。
みんなもapple.comってサイトには注意しましょうね。
www.youtube.com
とどいた!
12/12到着予定といいつつ11日になっても羽田から動いてなかったので大丈夫かーと思ったら11日深夜というか12日未明というかそのあたりには福岡に届いてて、朝発想されて夜にとどいた。
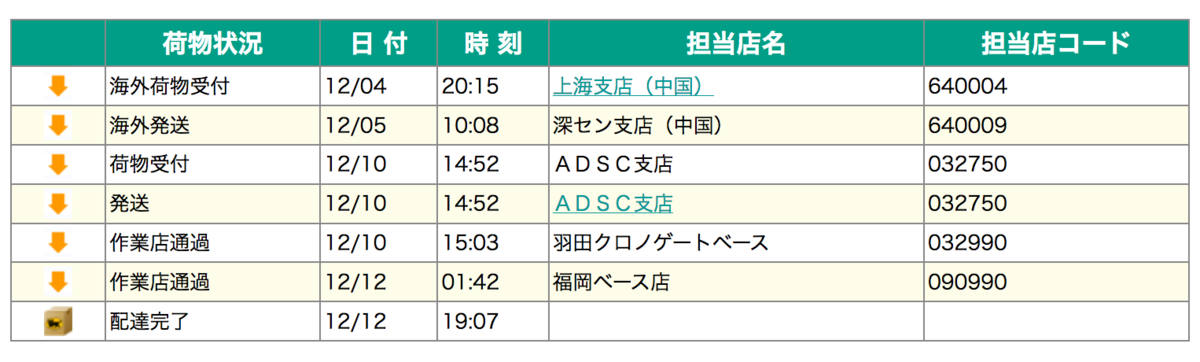
でこれだ!

ベンチマーク
GeekBenchも前評判どおりの値がでました。
 https://browser.geekbench.com/v5/cpu/5337092
https://browser.geekbench.com/v5/cpu/5337092
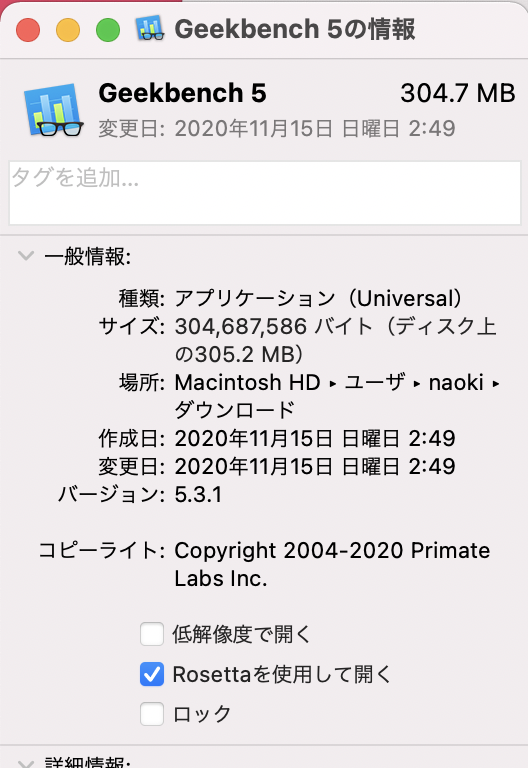
GeekbenchはUniversalAppになってるようで、アプリケーションの情報から「Rosettaを使用して開く」にチェックを入れるとx86版を動かすことができます。
プロセッサがVirtualAppleになっています。
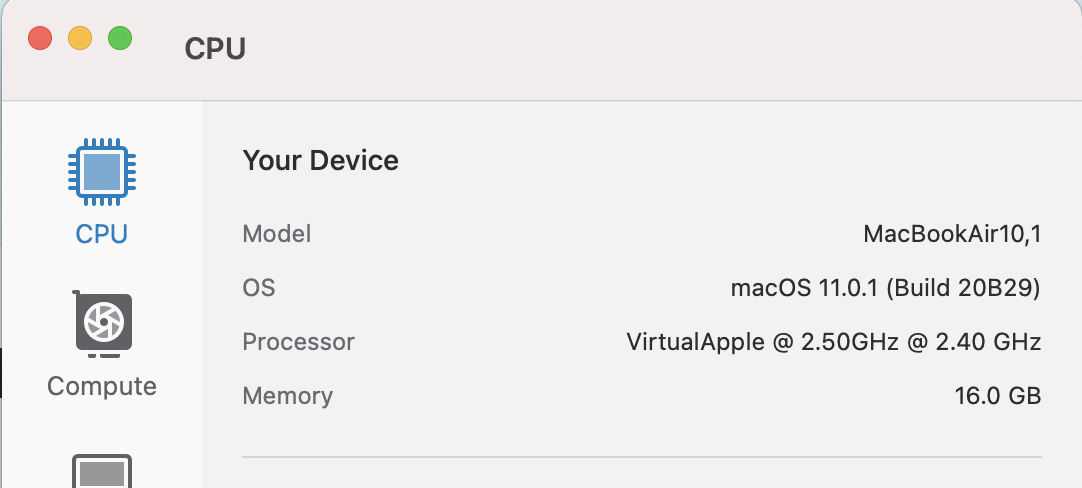
実行すると、Arm版を動かすのとほとんど同じ値が出ていますね。

https://browser.geekbench.com/v5/cpu/5337021
あと、7世代8コアi7(i7-7820X)が載ってるWindowsと7世代4コアi7(i7-7700HQ)が載ってるMacBook Pro 2017でベンチマークをとっています。
| M1 | VirtualApple | i7-7820X | i7-7700HQ | |
|---|---|---|---|---|
| Single-Core | 1735 | 1721 | 1023 | 767 |
| Multi-Core | 7345 | 7263 | 7606 | 2901 |
みてわかるのは、シングルスレッド性能は圧倒的に7世代i7たちをしのいでいますね。8コアi7はかろうじてマルチコア性能で勝ってますが、MacBook Pro 2017は完全に圧倒しています。これがエントリモデルであるMacBook Airていうところがすごいです。

GeekbenchはGPUの計測もできるので比較してみます。 。
| M7 | RTX2070 Super | Radeon Pro 555 | Intel HD Graphic 630 |
|---|---|---|---|
| 16692 | 94251 | 13165 | 4629 |
さすがにRTX 2070 Superにはぜんぜんかないませんが、MacBook Pro 2017にのってるRadeon Pro 555よりかなりパフォーマンスがいいですね。CPU内蔵のHD Graphicよりはかなりいいです。これがCPU内蔵のGPUってところがすごい

Javaのインストール
それでは、Javaを動かしてみます。
現在、JavaのArm Mac対応はJEP 391として進められていますが、3月リリースのJava 16には取り込まれず、おそらく9月リリースのJava 17に入ることになると思います。
とはいえAzul SystemsがArm Mac対応のJavaを出しているので、これを使って試してみます。
あと、x86版Javaも試してみようと思って、まずはzip版を落としてみるとCPUが違うといわれるました。このメッセージはキャプチャしそこねた。。。
Rosettaインストール後は警告が出ます。
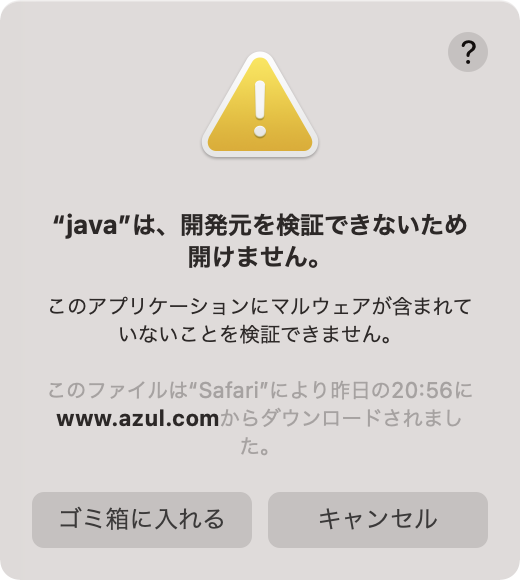
で、dmgをインストールしてみたのだけど、ここではAdoptOpenJDKでJava 11を使いました。インストールするときにRosettaのインストール確認が出たのだけど、これもキャプチャしそこね。もったいない。
NetBeansを動かす
NetBeans 12.2がArm Macに対応したということで、試してみました。
最初はZulu 16eaで動かしたんだけど、すぐ落ちていたので、Zulu 11だと安定しました。

x86 Java on RosettaでもNetBeans自体は動きました。
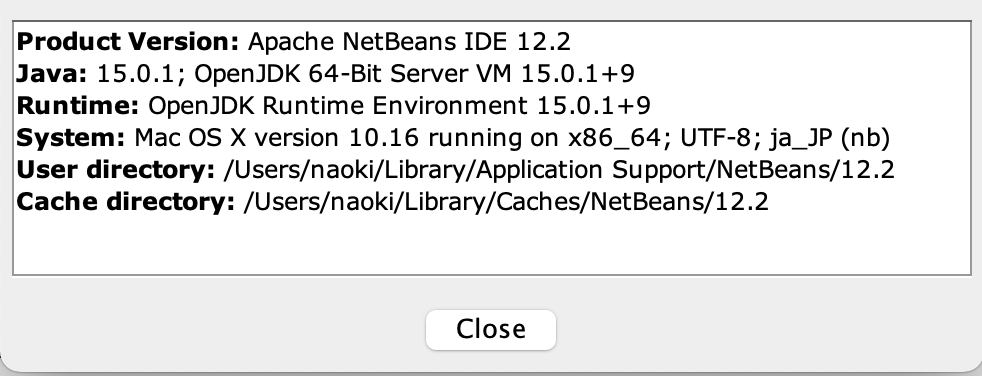
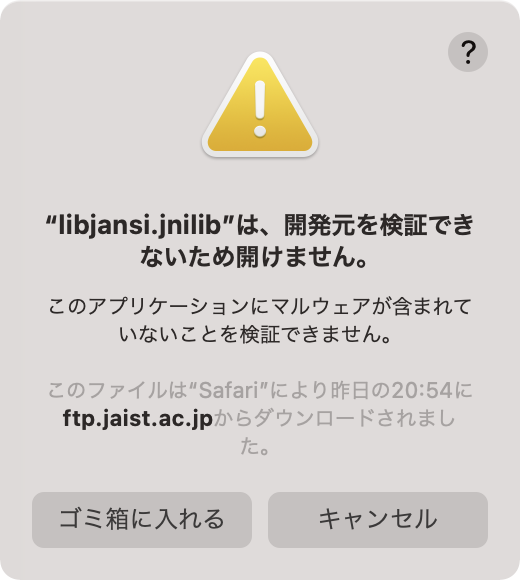
ところでRosettaで動かすとOSバージョンが10.16になってるの気になる。Arm版だと11.1です。
Arm JavaでNetBeansを動かしてもx86 Javaで動かしても、Arm JavaでMavenプロジェクトを動かすのは問題ないんだけど、x86 JavaでMavenプロジェクトを動かすとなんか怒られます。けどここでキャンセルするとビルドは行われる。
Gradleプロジェクトであれば、Arm Javaで動かしてもx86 Javaで動かしてもすんなりいけました。
レイトレでベンチマーク
いつもなんだかんだレイトレでベンチマークを取ってるので、ここでもやってみます。
SmallPTをJavaで書きなおしたものです。
https://github.com/kishida/smallpt4j/blob/original/src/main/java/naoki/smallpt/SmallPT.java
こんな感じの絵が出力されます。(ちゃんと時間をかければきれいになる)

それぞれ計ってみると、こんな感じになりました。単位は秒。
| M1 | VirtualApple | i7-7800X | i7-7700HQ |
|---|---|---|---|
| 9.3 | 10.7 | 5.9 | 14.6 |
実行時間なので、低いほど性能が高いです。
ほぼメモリアクセスなしの計算のみの処理で、ベンチマークよりはRosetta経由で性能劣化してるけど、CPUエミュレーションしてると考えればほぼ遜色ない性能といえると思います。コア数の差でi7-7800Xが有利ですが、MacBook Pro 2017のi7-7700HQよりはかなり速いですね。

メモリアクセスがあったほうがいいかとテクスチャありでも比較してみました。
https://github.com/kishida/smallpt4j

結果はこんな感じで、比率としてはほぼかわらずです。
| M1 | VirtualApple | i7-7800X | i7-7700HQ |
|---|---|---|---|
| 25.2 | 26.2 | 14.9 | 36.5 |
まあテクスチャ使うといっても、ほぼキャッシュに載ってしまってるのかなという感じでした。

Vector API
ついでに、Java 16ではSIMD命令をサポートするVector APIが取り込まれているので試してみます。x86であればAVX命令ですけど、ArmだとNEONですかね。
M1 Macでも使えて、doubleであれば2つの値を同時に計算できます。128bit幅ということですね。

レイトレでは3次元のベクトルを処理するために3つの値を同時に計算したいので、float x4にしてみたのですけど、精度不足のせいか変な絵になりました。

参考までに、処理時間としては12.6秒かかっているので、Vector APIを使わない場合の9.3秒と比べれば遅くなっています。これはx86のときも同様なので、まだJITの性能が出てないのかなという感じです。
Spring Boot
さて、もっと実用的なものということでSpring Bootを動かしてみます。
Spring InitializerでSpring Webを含めて作ったプロジェクトに簡単なコントローラを追加して起動時間を計っています。
@RestController @RequestMapping("/url") public class NewRestController { @GetMapping String hello() { return String.format("Hello %s on %s", System.getProperty("java.vm.name"), System.getProperty("os.name")); } }
Arm JDKだと起動に5.6秒かかってます。
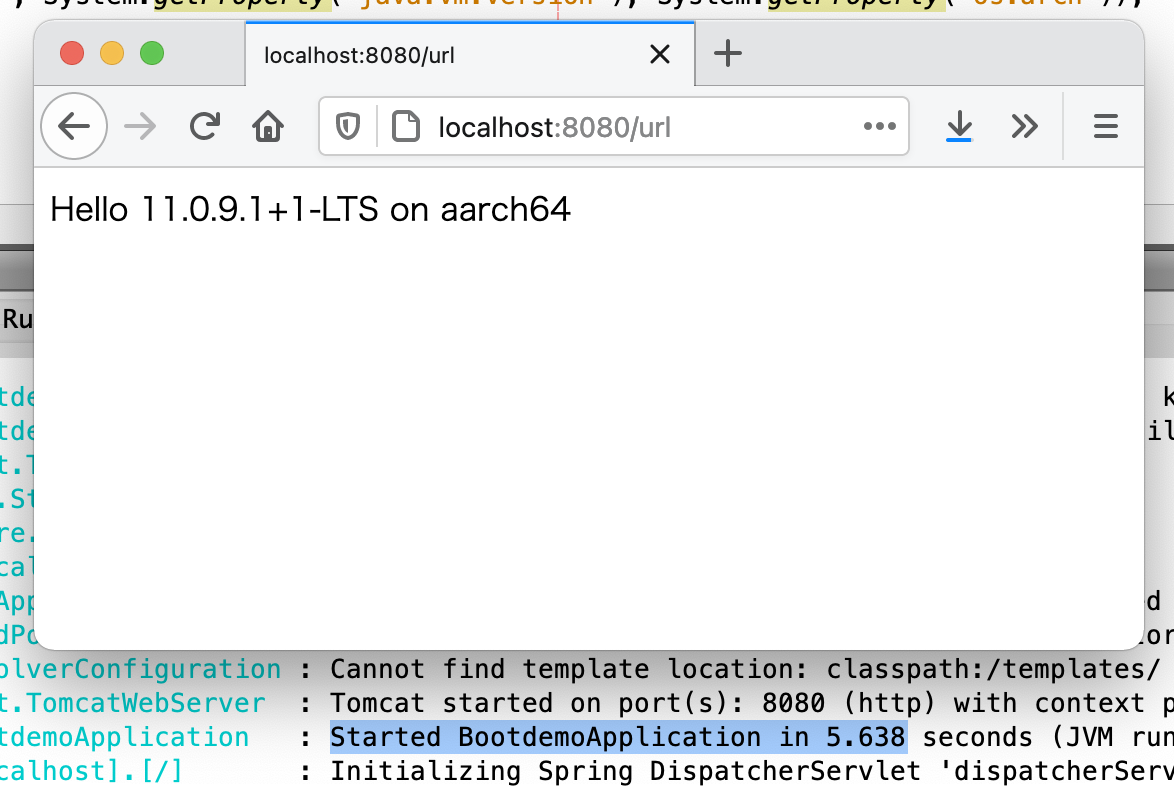
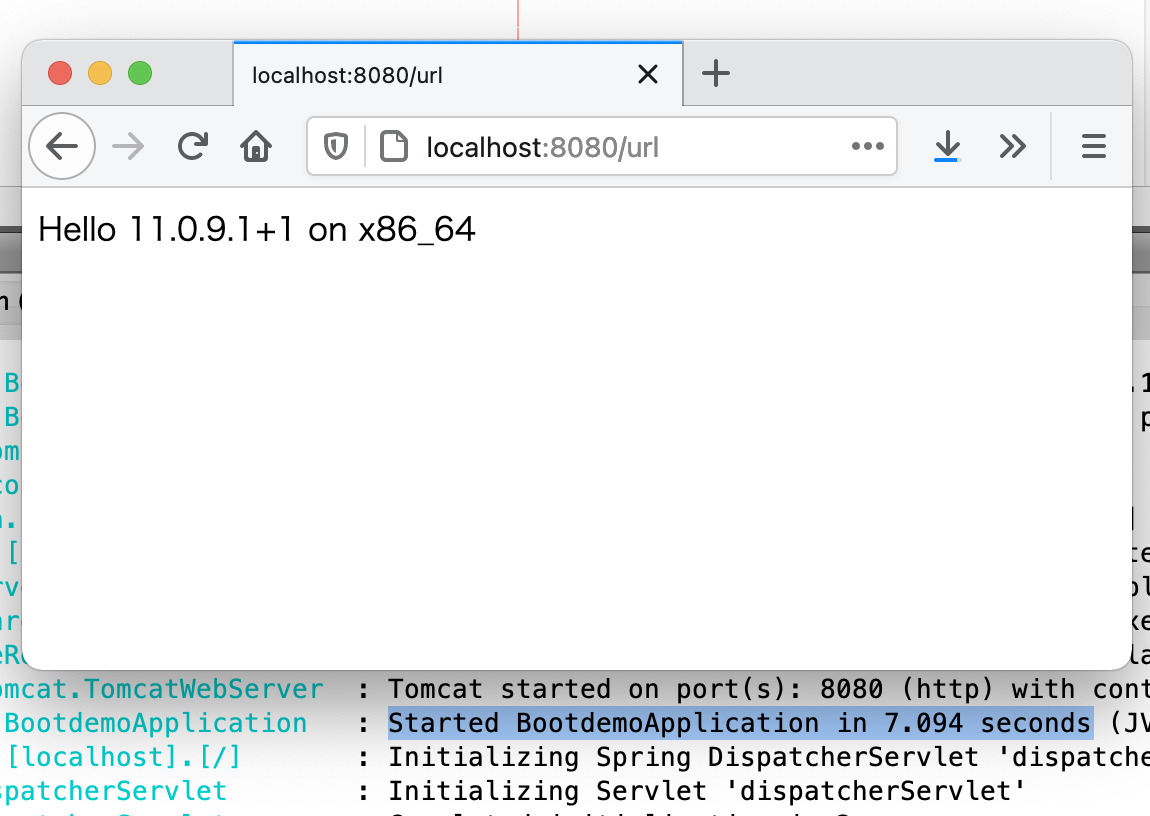
i7と比較してみると、やたら遅い感じです。
| M1 | VirtualApple | i7-7800X | i7-7700HQ |
|---|---|---|---|
| 5.6 | 7.1 | 1.5 | 1.5 |
Rosettaでも遅くなってるというのはありますが、MacBook Pro 2017と比べてもかなり遅くなっています。

見ているとAttaching agents: []のところで5秒かかっている感じです。なんらかセキュリティ機能でひっかかってるんでしょうか。
こちらでDockerで動かしたものと比較していますが、Dockerで動かした場合にはかなり起動が速くなっているので、プロセッサの問題ではなく、なんらかOSの問題でひっかかってるんではないかと思います。
Jibで作ったx86イメージがM1 Macで不安定。あとM1 BigSurでSpring Bootの起動が遅い - きしだのHatena
Kafkaのビルド
なんかまとまったソースのビルドのビルドを試そうと思って、ScalaのソースがいいなとKafkaをビルドしてみました。
すでに2.7.0がリリースされてるけど、試したのは2.6.0です。
https://kafka.apache.org/downloads
./gradlew releaseTarGzしています。

Rosetta経由だと表示が違うのは なんなんだろう?

--scanをつけて各タスクの時間を見るとこんな感じ。
こちらはM1 Mac。

こっちがi7-7800X Windows。

結果をまとめるとこんな感じ。
| M1 MacBook Air | M1 Rosetta | i7-7800X Windows | i7-7700HQ MBP 2017 |
|---|---|---|---|
| 1m27s | 3m39s | 2m59s | 3m56s |
M1Macはかなり速く、8コア i7の倍速以上になっていますね。コードのビルドは一般にマルチスレッド化しづらい処理なので、シングルコア性能が出ているんではないかと思います。
一方でRosettaはかなり遅く2.5倍の差がついていますね。レイトレではほとんど差がなかったので、シングルスレッドだとJIT結果が共有できなくて遅いとかディスクアクセスなどが弱いとかなんでしょうか。とはいえ、MacBook Pro 2017より速いので、実用上十分といえるのかもしれません。

Docker
DockerのM1 Mac対応はTech Previewとして開発されています。
https://docs.docker.com/docker-for-mac/apple-m1/
MacのDockerではx86イメージもArmイメージも動かせます。 x86 Macの場合ArmイメージはQEMUで、M1 Macの場合はx86イメージをQEMUで動かします。
ということで先ほどのレイトレをDockerで動かしてみます。
Dockerfileはこんな感じ
https://gist.github.com/kishida/0842ce696fc58b9809405d6714e0d7c9
JDKはGraalVMを使います。
https://github.com/graalvm/graalvm-ce-builds/releases/tag/vm-20.3.0
比較してみるとこんな感じ
| M1 | QEMU/Rosetta | i7-7800X | i7-7700HQ | |
|---|---|---|---|---|
| Docker | 9.4 | 3M32.3 | 7.3 | 18.8 |
| Host | 9.3 | 10.7 | 5.9 | 14.6 |
まあなんか、ホスト側とほとんどかわらないですけど、x86イメージをQEMU経由で動かしたものはかなり遅いです。
OSのコントロールできるRosettaと違って、OSごとのエミュレートだと不利なんだろうなという感じですね。複雑な処理が必要なものはあまり動かさないほうがよさそう。

Native Imageビルド
GraalVMにはJavaのコードをネイティブバイナリにコンパイルする機能があります。
せっかくGraalVMを使うのでNative Imageのビルドについても見てみます。
native-imageコマンドで、先ほどのレイトレーシングをネイティブ化してみます。
root@f9268a585b9a:/src# native-image SmallPT [smallpt:235] classlist: 949.93 ms, 0.96 GB [smallpt:235] (cap): 300.72 ms, 0.96 GB [smallpt:235] setup: 951.14 ms, 0.96 GB [smallpt:235] (clinit): 115.10 ms, 1.22 GB [smallpt:235] (typeflow): 4,217.23 ms, 1.22 GB [smallpt:235] (objects): 3,925.83 ms, 1.22 GB [smallpt:235] (features): 181.08 ms, 1.22 GB [smallpt:235] analysis: 8,624.17 ms, 1.22 GB [smallpt:235] universe: 266.92 ms, 1.22 GB [smallpt:235] (parse): 736.24 ms, 1.56 GB [smallpt:235] (inline): 947.00 ms, 1.56 GB [smallpt:235] (compile): 4,792.27 ms, 1.53 GB [smallpt:235] compile: 6,779.24 ms, 1.53 GB [smallpt:235] image: 769.52 ms, 1.52 GB [smallpt:235] write: 97.46 ms, 1.52 GB [smallpt:235] [total]: 18,542.54 ms, 1.52 GB
18秒かかってますね。 x86イメージをQEMUで動かした場合には、途中でコアダンプ吐いたりして、ネイティブ化ができませんでした。
| M1 | QEMU | i7-7800X | i7-7700HQ |
|---|---|---|---|
| 18.5 | N/A | 22.1 | 42.4 |
ビルド時間を比べてみると、8コアであるi7-7800Xよりも速くビルドが通っています。やはりシングルスレッド性能が出たのではないかと思います。

実行してみるとこんな感じです。QEMUではあらかじめi7で作成しておいたネイティブイメージを使っています。
| M1 | QEMU | i7-7800X | i7-7700HQ | |
|---|---|---|---|---|
| native-image | 21.4 | 5M28.7 | 34.2 | 48.2 |
| Java | 9.1 | 3M54 | 7.3 | 19.2 |
| 比率 | 2.4 | 1.4 | 4.7 | 2.5 |
ネイティブ化するまえ、Javaコードで動かした場合にはi7-7800Xのほうが速かったのですが、M1のほうが速くなっていますね。WindowsのDockerでなにかボトルネックがあるのかな。i7のCPU負荷が80%くらいにしかならなくて、ちゃんとコアが使い切れてない感じでした。
あと、QEMUでは差が小さいのが興味深いところ。実際の計算よりもエミュレーション用のなんらかのフットプリントのほうが時間をくってる感じでしょうか。

TensorFlow
M1にはニューラルユニットが載っているので、ニューラルネットワークの計算も得意なはずです。TensorFlowがM1 Macに最適化したAlpha版を出しているので、これを試してみます。
Releases · apple/tensorflow_macos · GitHub
まずはチュートリアルにある全結合層が2段のネットワークで試してみます。
https://gist.github.com/kishida/dc2c2a1c0eadea6708d991506e6b72d6
試してみるとこんな感じで6.2秒で終了しました。
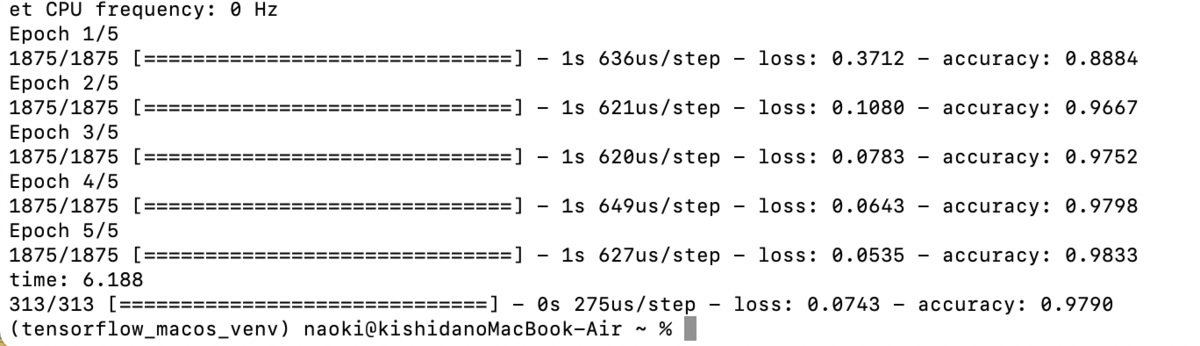
なんと、RTX2070 Superより速いですね。
| M1 | RTX2070 Super | i7-7700HQ |
|---|---|---|
| 6.2 | 11.8 | 19.9 |
グラフにするとこう

これは恐らく、ネットワークが小さいためRTX2070 Superのコアをほとんど使っておらず、データ転送だけで時間がかかってるのではないかという気がします。
また、M1でニューラルユニットとArmコアが同じメモリを見ているというユニファイドメモリのおかげでデータ転送不要になっているのも大きいのだと思います。
そこで、もっと大きいネットワークを作ってみます。
畳み込みニューラルネットワークのチュートリアルにある、
畳み込み層が3層、プーリング層が2層と全結合層が2層の、AlexNetに近いネットワークです。
https://gist.github.com/kishida/01d88f72fdf95170294d637d5d6d62f5
実行すると45.385秒になりました。

RTX 2070 Superなどと比較するとこんな感じです。
| M1 | RTX2070 Super | i7-7700HQ |
|---|---|---|
| 45.4 | 22.1 | 93.6 |

やはりサイズの大きいネットワークだとRTX 2070 Superより速いということはありませんでしたね。ただ、RTX 2070 Superの倍でしかない、ともいえるし、MacBook Pro 17 2017よりはかなり速いです。ノートパソコンとしてはかなり優秀なんじゃないでしょうか。
手元で機械学習をする場合にもよさそうです。
まとめ
やはり、かなりいいパフォーマンスが出てますね。
シングルスレッド性能が重要になりがちなビルドがかなり速くなっているので、エンジニアにはよさそうです。
GPUや機械学習もノートパソコンとしてはかなり高いパフォーマンスです。
まだDockerでのQEMUが不安定だったり、改善が必要な点はありますが、かなりよさげです。
オブジェクト指向には、カメラがやっとついたころのガラケーのイメージがある
某所でオブジェクト指向についていろいろ書いたのでまとめておく。
問題意識としては初学者がなにかというと「オブジェクト指向できるようになりたい」のようなことを言うけどそこまでの優先順位でがんばるものではないんでは、というところです。
まず前提として、オブジェクト指向は1980-2000年くらいに流行って発達したものの、それ以降は時代にあわせた進歩はしていない20年以上前の技術ってのがあります。
そのころは今だとCPUのキャッシュにも満たないようなメモリをやりくりしてプログラムを書く必要があったので、オブジェクト指向はメモリ上のデータをコピーすることなくうまく使いまわせるようなプログラム技術になっています。
そしてオブジェクト指向にはそこから目だった更新はなく、タイトルに書いたように、カメラがやっとついたくらいのガラケーのような古い技術という感じがします。
オブジェクト指向について、アプリケーションを組むときに考えるべき必須技術みたいな書き方がしてあると「いまはスマホの時代やで」に近い、もっと現代的な考え方ができるようにしようよという気持ちになります。
じゃあ現代的な考え方ってなんなのとなるけど、それはどちらかというと関数型になるんじゃないでしょうか。
関数型は実装としてはメモリをふんだんに使う仕組みになるので、昔は実用には厳しかったものの、いまでは8GBでも貧弱と言われるくらい余裕があるので、当たり前に使えるようになっています。
オブジェクト指向最盛期につくられたC++もJavaも、いまではラムダ式のような関数的構文をとりいれて、オブジェクト指向でプログラムを書くときの指針でもあったデザインパターンは、多くが「それラムダで素直にかけるよ」になっています。
あと、オブジェクト指向がどういうプログラミング技術だったのかを考えると「いかに状態をオブジェクトに閉じ込めて扱いやすくするか」という技術だったと言えます。
一方で関数型は「いかに状態を追い出して考えなくていいようにするか」という技術と言うこともできます。
オブジェクトと関数は視点の問題でもあって、オブジェクトで関数を実現することもできるし、関数でオブジェクトを実現することもできます。Javaのラムダ式はオブジェクトとして実現されていますね。
そして、いまの主流はWebアプリケーションで、サーバーサイドを書く場合には「ステートレス」つまり状態をもたないように書くことが基本になっています。状態はデータベースなどのストレージに格納されるようになってますね。そのようにアプリケーションに状態をもたないのであれば、状態を扱いやすくする必要はないので、関数型のほうが向いているということになります。
また、オブジェクト指向が発展した1980-2000年というのは、ユーザー端末にウィンドウシステムが取り入れられるようになった時期です。ユーザーインタフェースには、テキストボックスやボタンなどの部品の状態をうまく扱うことが求められるので、オブジェクト指向が相性がよく、オブジェクト指向とGUIは共に発展してきた面があります。
しかしいま、ユーザー端末もWebブラウザベースで作ることが基本になり、ブラウザの中では状態はDOMとしてすでに閉じ込められているので、アプリケーションとしてオブジェクトの状態を考える必要性は薄くなってきています。
さて、こう考えると、「なぜオブジェクト指向がわからないのか」という初心者がまどわされがちの疑問についても答えが見えてくると思います。
もしWebアプリケーションのサーバサイドを書きながら「なぜオブジェクト指向がわからないのか」と思っているなら、「あなたの書いてるコードにはオブジェクト指向が不要だからです」が答えになります。サーバーサイドにはオブジェクト指向があまり向いていないので、いかにうまくオブジェクト指向で書こうとしても「しっくりこない」「わからない」ということになっていくと思います。
オブジェクト指向がむいているはずであったGUIにしても、いまどきのGUIフレームワークであればあまりオブジェクト指向を考える必要なく、関数をイベントに割り当てていくだけでアプリケーションを組むことができるようになっています。そのため、GUIアプリケーションでさえ、「オブジェクト指向がしっくりこない」になりがちです。
JavaのSwingを使ってUIを作る場合であれば、オブジェクト指向だなーという感じになりますが、より新しいJavaFXを使ってUIを作るときは あまりオブジェクト指向感はありません。(個人の感想です)
こういうことを書くと「いやいやモジュール化や開放/閉鎖原則のような、プログラムを組むうえでの大事な考え方がオブジェクト指向にはあるじゃないか」というツッコミもあるかもしれませんが、そういったソフトウェア構築の大事な原則というのは、オブジェクト指向がうまく取り込んだだけであって、オブジェクト指向が必須というわけではありません。
プログラムの構成単位がオブジェクトなのであれば、それらの原則を適用するためにオブジェクト指向が必要になりますが、いまどきの言語は関数が独立して扱えるようになっているので、オブジェクト指向にこだわる必要はなくなっています。
もちろん、いまのスマホが昔のガラケーがあったからこそ成り立っているように、いまのソフトウェア技術もオブジェクト指向があったからこそ成り立っているという面もあります。
オブジェクト指向全盛の時代につくられたJavaであれば、オブジェクト指向をわかっていれば使いやすいところもたくさんあります。
アプリケーション全体としてオブジェクト指向で考えることが向かない場合でも、部分的にはオブジェクト指向的に考えたほうがすんなりいくこともあります。
その意味ではオブジェクト指向は習得していると有利な考え方ではありますが、プログラムを組むためにオブジェクト指向は理解するべきというほどの必然性はなくなっています。
いまでは各言語に実装されているオブジェクト指向的機能を使えれば十分で、「オブジェクト指向を理解する」のように肩ひじはって考えるのではなくて、Javaであればclassの継承やinterfaceの使い方を理解するというように、目の前の機能に向き合えば十分な気もします。それらにしてもWebアプリケーションであれば自分で理解して書く機会はそこまで多くないので、初心者のひとが「オブジェクト指向がわかりません」と言ってるのを見ると、じゃあそれはほっといて まずはアプリケーション書こうぜって気持ちになります。
また、いろいろな言語にオブジェクト指向的機能が取り入れられてますが、それぞれの言語によって違いがあり位置づけも違うため「オブジェクト指向」とひとまとめに扱えるものではなくなっています。その意味でも、目の前の言語機能に向き合うことのほうが大事になってると思います。
まとまらないので、ここまで。
そして最後に取り上げるのがこんな本かという感じですが、この他の著者のかたがオブジェクト指向について書いている中で「オブジェクト指向はまぼろしか?」という記事で、オブジェクト指向の歴史的な流れから、どのようにオブジェクト指向は使われなくなったかということを書いています。

よくみると定期的にオブジェクト指向について書いてるな。これらは7年前のもの。
オブジェクト指向は禁止するべき - きしだのHatena
オブジェクト指向について - きしだのHatena
1/22追記
この「オブジェクト指向について」でも書いてますが、基本的にぼくの「オブジェクト指向」はランボーのOMTに従っています。世の中でよく言われている「オブジェクト指向」もOMTを源流のひとつとして熟成され ただよってるものだと思います。
そこでランボーはオブジェクト指向とは「データ構造と振る舞いが一体となったオブジェクトの集まりとしてソフトウェアを組織化すること」と呼んでます。
個人的には、ソフトウェアの全体、もしくはその機能の全体をオブジェクトの集まりとして組織化するのであればオブジェクト指向の勉強は必要だと思いますが、その機会は少なくなっているし、単にデータと操作をまとめて扱いやすくするとかデータの分類を継承によるサブクラス化で行う程度であれば言語機能の理解で充分ではないか、と思います。
クラスライブラリやフレームワークをうまく使いたいという話であれば、それを使うための言語機能を勉強することを「オブジェクト指向」というのは、おおげさではないかと。

小樽ビール - おいしそうなノンアルコールビール飲み比べ
ノンアルコール飲み比べエントリを書いていましたが、小樽ビールを試してみたので追記しつつ、独立したエントリにもしておきます。
nowokay.hatenablog.com
小樽ビールのノンアルで、ラガータイプと黒ビールタイプがあってどちらもおいしい。黒は他になかなかないので貴重。


ラガータイプのほうは麦の甘さが出た感じで、なぜかコーンの味がします。コーンは入ってないけど。この甘さが気に入ればいいけど、ビールとしては甘すぎるかなという感じ。
黒のほうはそういった甘さもなく、かといって苦すぎず味のバランスもいい感じ。これはおすすめ。
どちらも原材料は「麦芽、ホップ」です。黒は黒ビールと同じく麦芽をローストして使ってるみたい。
11月にみつけて、11/16発売予定だったノンアルヒューガルデンが来たら一緒に追記しようと思ってたけど、いまだに発売されてないので追記
ラガータイプはメーカーからは品切れぽく、こちらから買えます。
1本あたり324円。メーカー直じゃないのでだいぶ割高

2021/10/03時点では在庫あり

黒タイプは在庫有。こちらは1本あたり208円です。

プログラムを教えて理解されない場合は教える技術の不足
プログラムが組めるとプログラムが教えれると思いがちだけど、教えることは別の技術です。
教えてもなかなか理解してくれないとき、プログラミングに向いてないとさえ言う人もいますが、教える側の教える技術の不足です。
教えることも技術のひとつだと気付けば、教えてもなかなか理解してくれないときに技術の不足であるということにも思い至れると思います。技術の不足であると気付けば、改善もしていけます。
そして教える技術というのは、インストラクショナルデザインという名前で系統だてて整理されています。
たとえばそのまま「インストラクショナルデザイン」など、タイトルにインストラクショナルデザインが含まれた書籍もたくさん出ています。

- 作者:島宗 理
- 発売日: 2004/11/01
- メディア: 単行本
他にも、タイトルにはインストラクショナルデザインとついてないけどインストラクショナルデザインの本というのもあります。

世界一わかりやすい教える技術
どちらの本にも、うまく教えれないなら教えられる側ではなく教える側の問題、というようなことが書いてあります。
「インストラクショナルデザイン」では「学び手は常に正しい」、「いちばんやさしい教え方の技術」では「結果が思わしくないのは、すべて教える側の責任」とあります。

1/8追記:「学び手は常に正しい」と「お客様は神様」を同列視してるコメントがありますが、そういうことではないということを、どちらの本にも書いてあります。
ということで、教える仕事をするときにはインストラクショナルデザインについて軽く知っておくといいのですけど、とりあえずは教えることも技術のひとつであることを知っておけば、うまく教えれないときに学ぶ側ではなくて教える側の技術不足だと気づけます。それさえ気づければ、ある程度は自力で改善できると思います。
システム開発を受注した側が「客の要求があいまいだしころころ変わる」みたいな文句を言ってることがありますが、要件定義もひとつの技術であることを知ってれば、要件定義の技術が不足しているとわかって改善していけるのと同じです。
話はそれますが、要件定義についてはこのあたり読むといいんじゃないでしょうか。

あと、「いちばんやさしい教え方の技術」には、教える技術は教える仕事をするときだけではなく生活の中でわりと使えるというようなことが書いてあります。
会話の中でものごとを説明する必要がでることも多いと思いますが、そういうときに結構やくに立ちます。
ということで、興味があれば、一度インストラクショナルデザインについて軽く調べてみるといいと思います。