以前のエントリで、GPTのEmbeddingを使ったベクトルデータでブログの「方向性」を登録して、検索語やブログに近いブログを探すというのをやりました。
これ、少し高速化できるかなと、やってみました。
結論としてはList
GPTのEmbeddingを利用してブログの投稿に対する近いものを探し出す - きしだのHatena
※ 本格的に高速化したい場合はFaissやElasticsearchのANNなどの専用インデックスを使いましょう。

元コード
内積を計算する部分を高速化していきます。
元コードはこんな感じです。15回実行します。
TreeSet<Score> ts = new TreeSet<>( (s1, s2) -> Double.compare(s1.score(), s2.score())); for (var n = 0; n < 15; ++n) { for (var e : entries) { if (!e.published() || e.stripedBody().length() < 50 || deny.contains(e.title())) { continue; } double score = 0; for (int i = 0; i < vector.size(); ++i) { score += vector.get(i) * e.vector().get(i); } ts.add(new Score(-score, e)); while (ts.size() > 4) ts.remove(ts.last()); } }
2回ほど計測したあと5回計測するとこんな感じ。(単位はミリ秒)
243 233 234 238 234
Streamに変えてみる
内積をとるにはお互いのベクトル成分を掛けて足すだけなのだけど、その部分をStreamで書いてみます。
TreeSet<Score> ts = new TreeSet<>( (s1, s2) -> Double.compare(s1.score(), s2.score())); for (var n = 0; n < 15; ++n) { for (var e : entries) { if (!e.published() || e.stripedBody().length() < 50 || deny.contains(e.title())) { continue; } double score = IntStream.range(0, vector.size()) .mapToDouble(i -> vector.get(i) * e.vector().get(i)) .sum(); ts.add(new Score(-score, e)); while (ts.size() > 4) ts.remove(ts.last()); }
結果はこう。
368 364 361 362 361
遅くなりましたね。
並列Stream
じゃあ並列化したらどうか。parallel()をつけます。
TreeSet<Score> ts = new TreeSet<>( (s1, s2) -> Double.compare(s1.score(), s2.score())); for (var n = 0; n < 15; ++n) { for (var e : entries) { if (!e.published() || e.stripedBody().length() < 50 || deny.contains(e.title())) { continue; } double score = IntStream.range(0, vector.size()) .parallel() .mapToDouble(i -> vector.get(i) * e.vector().get(i)) .sum(); ts.add(new Score(-score, e)); while (ts.size() > 4) ts.remove(ts.last()); } }
結果はこう。
425 429 439 424 432
さらに遅くなってます。map処理が軽い場合は並列化のオーバーヘッドのほうが大きくなるので、遅くなってるようです。
TreeSet -> 配列
じゃあ内積部分をもとに戻して、TreeSetを使って上位4件を取ってるところを配列にしてみます。
Score[] ts = new Score[4]; for (var n = 0; n < 15; ++n) { ts = new Score[4]; for (var e : entries) { if (!e.published() || e.stripedBody().length() < 50 || deny.contains(e.title())) { continue; } double score = 0; for (int i = 0; i < vector.size(); ++i) { score += vector.get(i) * e.vector().get(i); } var s = new Score(-score, e); for (int i = 0; i < ts.length; ++i) { if (ts[i] == null) { ts[i] = s; break; } else if (ts[i].score() > s.score()) { var tmp = ts[i]; ts[i] = s; s = tmp; } } }
結果はこう。速くなりました!
202 202 204 204 201
List -> double[] その1
Doubleのリストを使っていたものをdoubleの配列にします。
まずは比較元になるデータだけ。
double[] ve = vector.stream().mapToDouble(Double::doubleValue).toArray(); Score[] ts = new Score[4]; for (var n = 0; n < 15; ++n) { ts = new Score[4]; for (var e : entries) { if (!e.published() || e.stripedBody().length() < 50 || deny.contains(e.title())) { continue; } double score = 0; for (int i = 0; i < vector.size(); ++i) { score += ve[i] * e.vector().get(i); } var s = new Score(-score, e); for (int i = 0; i < ts.length; ++i) { if (ts[i] == null) { ts[i] = s; break; } else if (ts[i].score() > s.score()) { var tmp = ts[i]; ts[i] = s; s = tmp; } } } }
ちょっと速くなってますね。
195 193 189 189 193
List -> double[] その2
データ保持も含めて、ぜんぶdouble配列にします。
レコードの型も。
public record BlogEntryArr ( BlogEntry entry, double[] vector) {}
データ作る部分を変更
List<BlogEntryArr> entries = baseEntries.stream()
.map(ent -> new BlogEntryArr(ent, ent.vector().stream().mapToDouble(Double::doubleValue).toArray()))
.toList();
処理はこんな感じに。
private static void printRelated(PrintWriter pw, List<BlogEntryArr> entries, List<Double> vector, boolean removeTop) { record Score(double score, BlogEntry entry) {} var start = System.currentTimeMillis(); double[] ve = vector.stream().mapToDouble(Double::doubleValue).toArray(); Score[] ts = new Score[4]; for (var n = 0; n < 15; ++n) { ts = new Score[4]; for (var e : entries) { if (!e.entry().published() || e.entry().stripedBody().length() < 50 || deny.contains(e.entry().title())) { continue; } double score = 0; for (int i = 0; i < vector.size(); ++i) { score += ve[i] * e.vector()[i]; } var s = new Score(-score, e.entry()); for (int i = 0; i < ts.length; ++i) { if (ts[i] == null) { ts[i] = s; break; } else if (ts[i].score() > s.score()) { var tmp = ts[i]; ts[i] = s; s = tmp; } } }
すげー速くなってます。List
91 68 67 68 68
15回処理だったものを100回処理に変更
450 451 461 489 473
double -> float
doubleをfloatにしてみます。
こんな変換をかけていく。
static float[] doubleListToFloatArray(List<Double> vector) { float[] ve = new float[vector.size()]; for (int i = 0; i < ve.length; ++i) { ve[i] = vector.get(i).floatValue(); } return ve; }
100回だとこう。微妙に速くなってますね。
435 414 426 418 418
Vector APIを使う
さて、Vector APIを使ってSIMD処理をしてみます。
コンパイルや実行には--add-modules jdk.incubator.vectorが必要です。
importする。
import jdk.incubator.vector.*;
int pos = 0; VectorSpecies<Float> species = FloatVector.SPECIES_256; FloatVector sum = FloatVector.zero(species); for (pos = 0; pos < vector.size(); pos += species.length()) { FloatVector vecA = FloatVector.fromArray(species, ve, pos); FloatVector vecB = FloatVector.fromArray(species, e.vector(), pos); sum = vecA.mul(vecB).add(sum); } double score = sum.reduceLanes(VectorOperators.ADD); for (; pos < vector.size(); pos++) { score += ve[pos] * e.vector()[pos]; }
100回実行でこれ。めちゃ速くなった!3倍近く高速化しています。
146 144 162 146 147
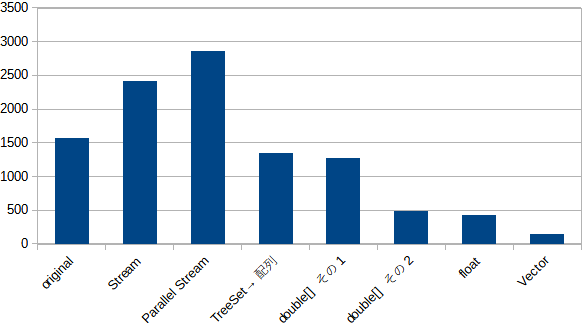
結果
100回処理換算で並べてみるとこんな感じ
| 実行時間 | |
|---|---|
| 元コード | 1576 |
| Stream | 2421 |
| Parallel Stream | 2865 |
| TreeSet->配列 | 1350 |
| double その1 | 1278 |
| double その2 | 464 |
| float | 422 |
| Vector API | 149 |